

LMArena: How the Web’s Biggest LLM Leaderboard Works
FREEAI engineers, ML/LLM evaluators, and product teams who need a fast, practical way to shortlist and route LLMs using human-preference signals (and who want to understand Elo/CI caveats to avoid overfitting to the leaderboard).
An Elo-style rating derived from large-scale pairwise human preferences in anonymous model battles.
How to use LMArena without getting fooled
Don’t pick a global #1—build a routing plan validated on your real prompts.
Use anonymous Battle Mode for a fast human-preference shortlist signal.
Treat small Elo gaps as noise when 95% confidence intervals overlap.
Pick per-task winners (Coding vs Long Context vs Domain QA) and route in production.
Re-check periodically; model updates and leaderboard drift are normal.
It’s 6:40 p.m. and your release train leaves tomorrow.
Two models are neck-and-neck—but one crushes long prompts while the other shines on code diffs. You open LMArena, run 20 real prompts across Overall → Coding → Longer Query, then try your repo in RepoChat using repo-aware code assistants (why "agentic" is not the same as "coding"). By 7:15 p.m., the pattern is obvious: route by task, note the trade-offs, and ship with confidence.
Answer in 30 seconds
If you need a fast, human-preference signal to shortlist LLMs, use LMArena: run anonymous battles with your real prompts, interpret small Elo gaps as noise (use the confidence interval), and pick per-task winners instead of a single global #1. Build a router-first blueprint for production routing, then re-check periodically because leaderboards and models drift.
What LMArena is (in 60 seconds)
LMArena (ex–Chatbot Arena) is a public leaderboard where people compare LLM answers head-to-head. Each anonymous vote updates an Elo-style rating. It’s ideal when you need to choose a model for a task (coding, web dev, long prompts, etc.) and want a human-preference signal—not just static benchmarks.
How it works (1-minute version)
- Anonymous battles: two models answer the same prompt; you vote before names reveal.
- Arena Elo: votes update ratings; leaderboard also shows MT-Bench and MMLU panels to triangulate quality.
- Only anonymous battles move Elo: Side-by-Side is for labeled comparison; it doesn’t affect scores (see: [1], [2], and the official [3]).
Snapshot (as observed on Feb 19–21, 2026)
Rankings drift. Treat tables as snapshots, and re-check the live leaderboards before you ship: [4], [5], [6].
If you want to track changes without re-reading this guide, follow the official changelog: [7].
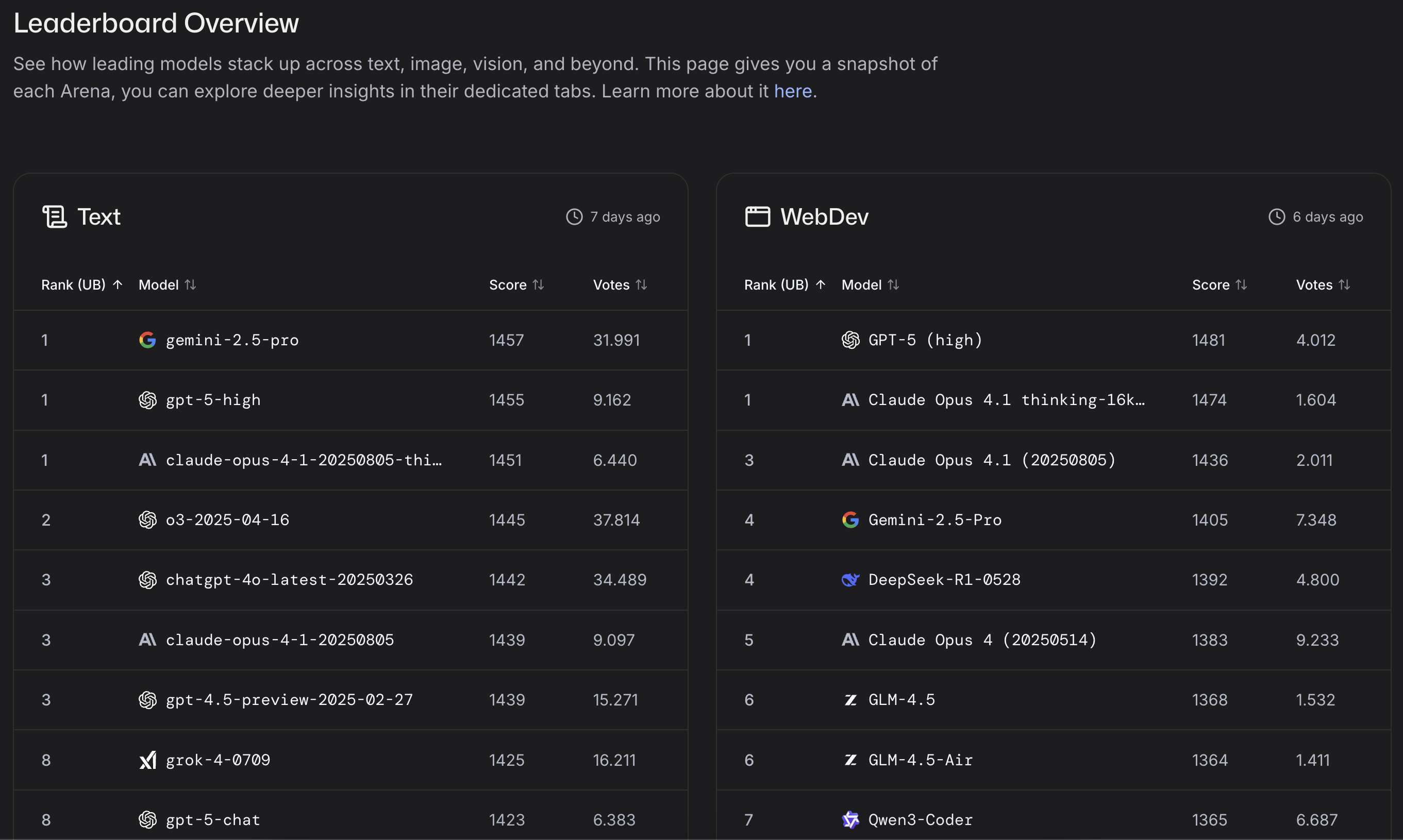
Text Arena — Overall (as of Feb 21, 2026)
| Rank | Model | Score |
|---|---|---|
| 1 | claude-opus-4-6-thinking |
1505±8 |
| 2 | claude-opus-4-6 |
1505±8 |
| 3 | gemini-3.1-pro-preview |
1500±9 (preliminary) |
| 4 | gemini-3-pro |
1486±4 |
| 5 | gpt-5.2-chat-latest-20260210 |
1478±12 |
| 6 | dola-seed-2.0-preview |
1474±10 (preliminary) |
| 7 | gemini-3-flash |
1474±5 |
| 8 | grok-4.1-thinking |
1473±4 |
| 9 | claude-opus-4-5-20251101-thinking-32k |
1472±4 |
| 10 | claude-opus-4-5-20251101 |
1467±4 |
Treat “Model” strings as leaderboard labels. Small gaps near the top are often noise unless confidence intervals separate.
WebDev Arena (Code Arena | WebDev) — snapshot (as of Feb 19, 2026)
Top signals:
claude-opus-4-6leads with 1561 (+14/-14)claude-opus-4-6-thinkingfollows at 1551 (+16/-16)claude-sonnet-4-6is #3 at 1524 (+20/-20)- Several models cluster tightly behind, with overlapping CIs.
Code Arena (WebDev) — as of Feb 19, 2026
| Rank | Model | Score |
|---|---|---|
| 1 | claude-opus-4-6 |
1561 +14/-14 |
| 2 | claude-opus-4-6-thinking |
1551 +16/-16 |
| 3 | claude-sonnet-4-6 |
1524 +20/-20 |
| 4 | claude-opus-4-5-20251101-thinking-32k |
1501 +8/-8 |
| 5 | gpt-5.2-high |
1471 +16/-16 |
Editorial note: today’s top cluster spans multiple vendors (e.g., Google, OpenAI, Anthropic, xAI), which is exactly why “route by task” beats “pick a global #1” (see this case study on specialization vs a single global winner).
What changed since 2025 (how to keep this guide current)
LMArena evolves fast: new models enter, arenas change, and methodology updates get logged publicly.
My rule: treat leaderboard tables as snapshots and track changes via:
- the live leaderboards,
- the Leaderboard Changelog (methodology + additions),
- periodic re-checks on your prompt set.
Notable recent examples include new model additions to the Code leaderboard and broader evaluation updates logged in the official changelog: [7]. For product experiments that can affect how people use the Arena, see: [8].
Under the hood: Elo in 90 seconds
Mental model: LMArena is doing pairwise ranking at massive scale. Instead of asking people to score models on an absolute 1–10 scale, it asks a simpler question: “Which answer wins?” That tends to reduce rater variance and produces a more stable ordering.
- Elo is relative. A model’s rating is updated by wins/losses vs opponents on the prompts it actually faced.
- Confidence intervals (CI) matter. When two models’ 95% CIs overlap, a small gap (e.g., +5–15 Elo) is often indistinguishable from noise.
- Selection bias is real. If a model mostly fights certain opponents or prompt types, its Elo reflects that mixture—not a universal “IQ” (see LLM evaluation: Goodhart, regression tests, and eval pitfalls).
Big gap + non-overlapping CI → likely real difference
Tiny gap + overlapping CI → treat as a tie; break with your prompts
Three ways to use LMArena (hands-on)
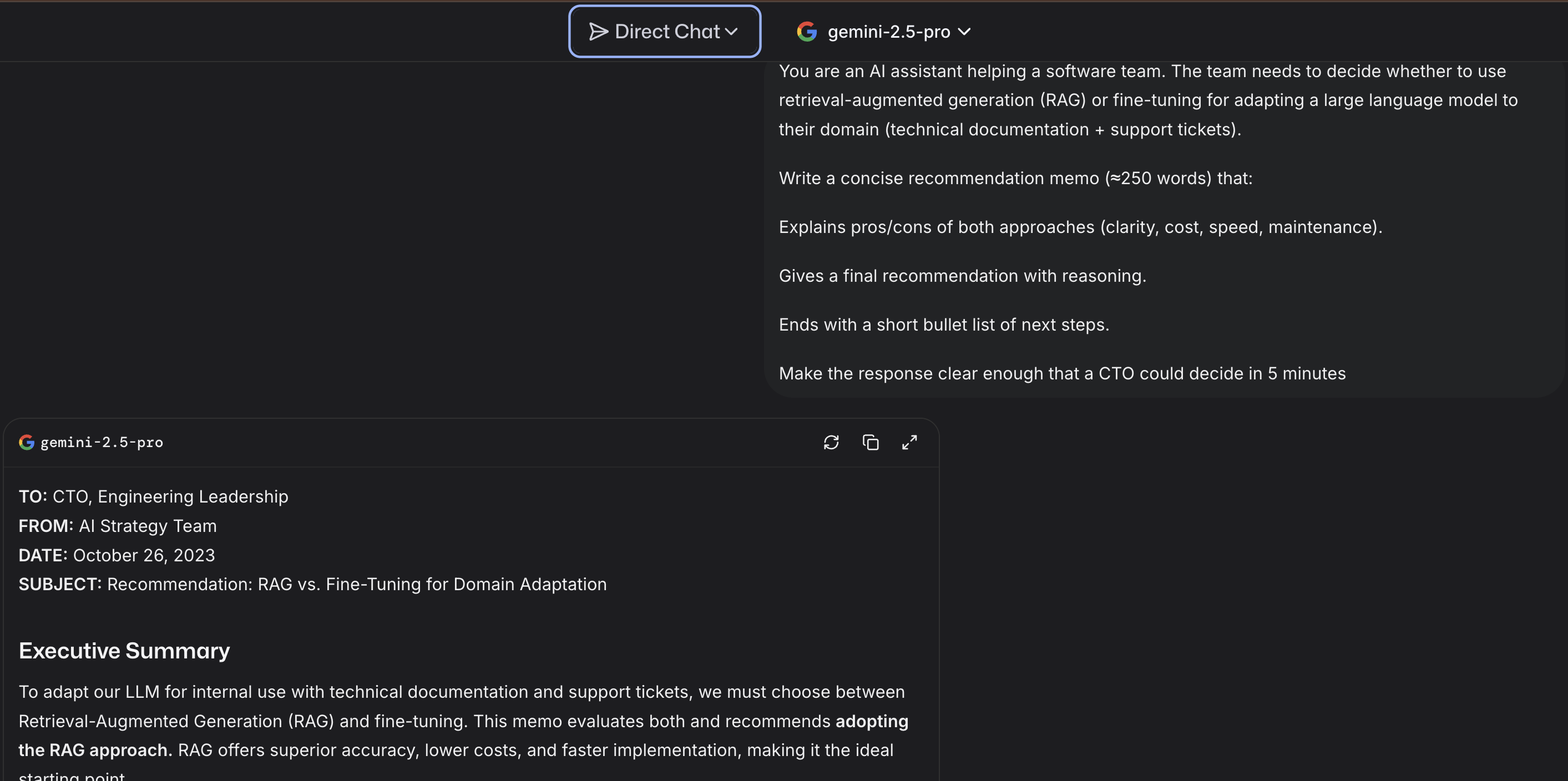
1) Direct Chat — fast single-model sanity check
Use when you want one good draft quickly (tone/style, first pass).
Paste this prompt to try:
You are an AI assistant helping a software team. The team needs to decide whether to use retrieval-augmented generation (RAG) or fine-tuning for adapting a large language model to their domain (technical documentation + support tickets).
Write a concise recommendation memo (~250 words) that:
- explains pros/cons of both (clarity, cost, speed, maintenance),
- gives a final recommendation with reasoning,
- ends with Next steps bullets.
Make it clear enough that a CTO could decide in 5 minutes.
What to look for: structure, trade-off clarity, actionable next steps.
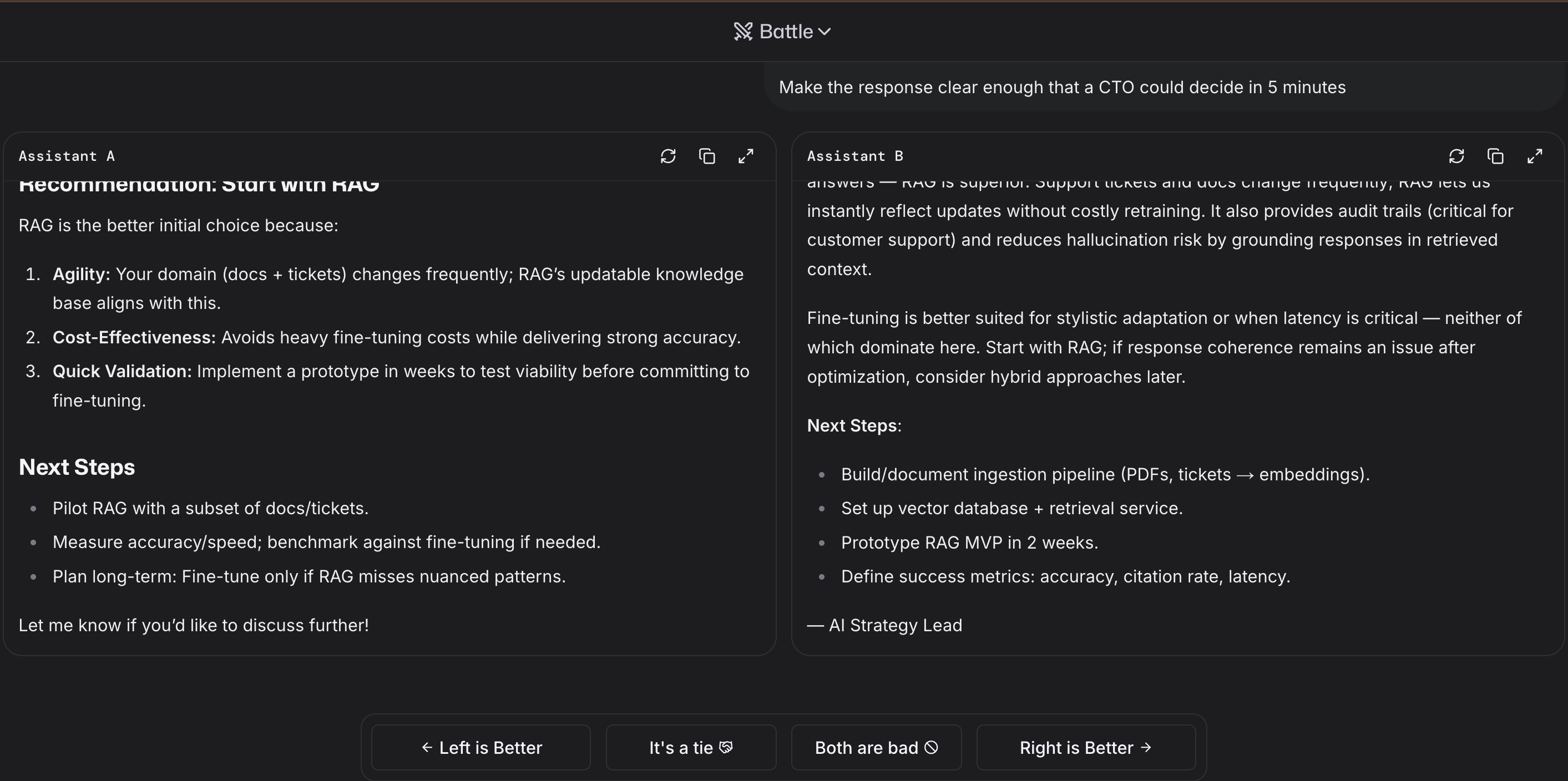
2) Battle — anonymous A vs B (you vote after reading)
Best when you’re deciding between two candidates and want blind judgment.
How to run a good battle
- Paste a real prompt from your backlog.
- Read both answers before names reveal.
- Vote for the one you’d ship to a user today.
Quick rubric: correctness → reasoning → instruction-following → conciseness → citations (if any).
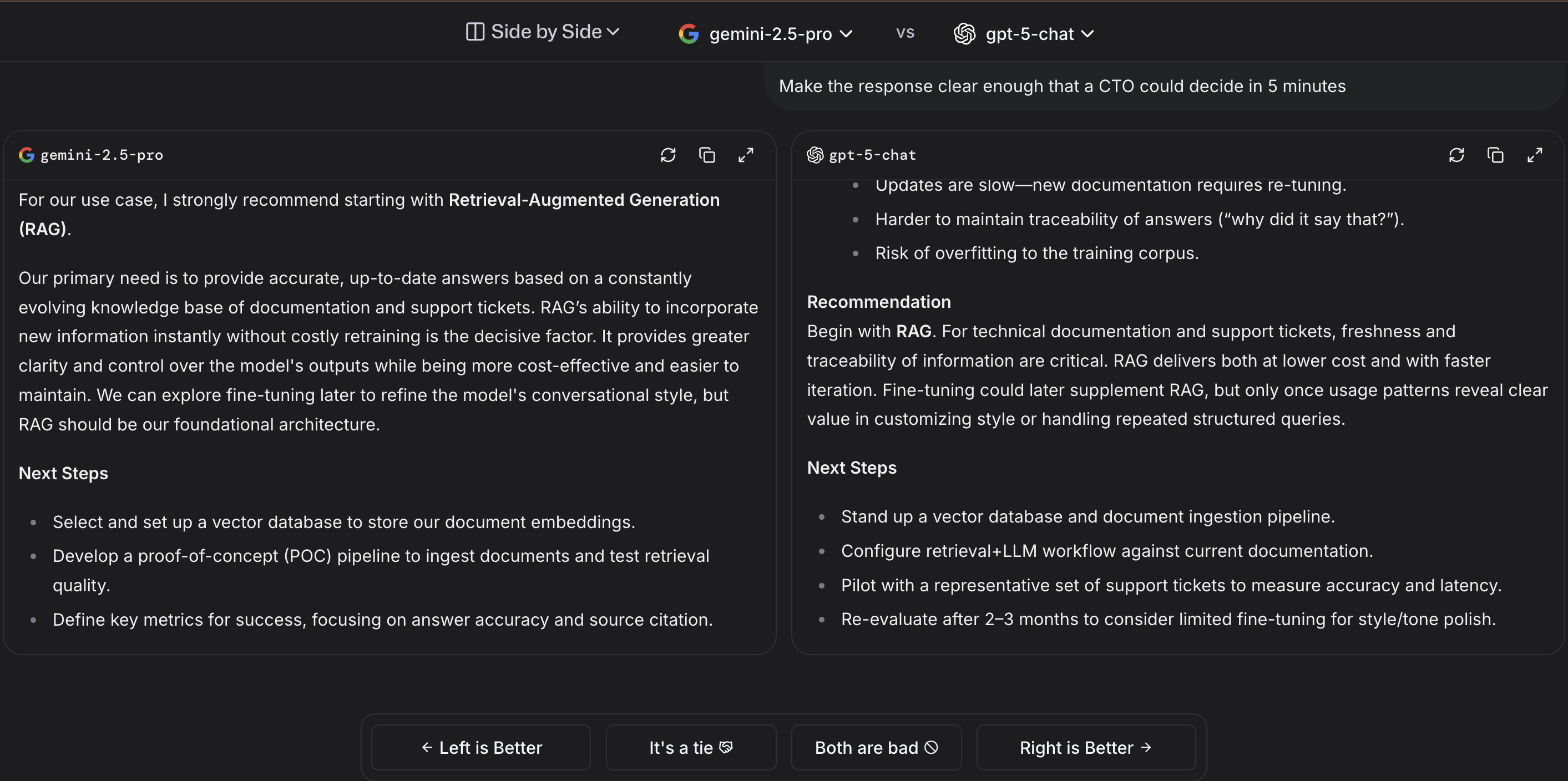
3) Side-by-Side — explicit model vs model
Pick two finalists (e.g., gemini-2.5-pro vs claude-opus-4.1-20250805-thinking-16k) for a labeled comparison.
Tips
- Keep the same prompt across runs to compare apples to apples.
- Do 5–10 prompts per task (long spec, coding bug, data wrangling).
- Note failure modes: latency spikes, hallucinations, messy formatting.
How to read the leaderboard without overfitting
- Start with the right tab. If you ship front-end code, WebDev matters more than Text “Overall”.
- Triangulate. Elo is human preference; cross-check the MT-Bench/MMLU panels shown next to rows.
- Beware tiny gaps. A few points at the top are often noise—use battles on your prompts to decide, and keep your grounding solid with IR basics (keyword vs semantic retrieval).
Key takeaways (for production teams)
- Treat Elo as a shortlist signal, not a final decision.
- Break near-ties with your prompts, latency, and failure-case tests.
- Prefer routing by task (coding vs long context vs domain QA) over a single “best model”.
- Re-check monthly (or before major launches): model updates and leaderboard drift are normal.
A 20-minute evaluation recipe (teams)
- Collect 6–8 real prompts (2 coding, 2 long-form, 2 domain-specific).
- Shortlist 3 models from the relevant tab.
- Run 10 battles total (shuffle pairs).
- Record winners + notes (reasoning, latency, formatting).
- Pick per-task winners; route in prod by task if needed.
Lightweight monthly health-check
- 6 prompts × 3 categories (Coding, Longer Query, Your Domain)
- 6–10 battles per category vs last month’s winner
- Log: win rate, latency, formatting, citation quality
- Update your router only if deltas persist across two checks (use this guide on how to route queries: CAG vs RAG)
Related reading (internal)
- Retrieval basics:
/learn/expert/introduction-to-information-retrieval-systems - RAG architecture & trade-offs:
/learn/expert/cag-vs-rag - RAG & context engineering hub:
/topics/rag - Production fundamentals (context/tokens/tool use):
/learn/midway/llm-practical-fundamentals-guide-ai-apps - 2026 enterprise playbook (agents, evaluation, governance):
/learn/midway/generative-ai-roadmap-2026-enterprise-playbook
Curiosity bites
- Side-by-Side ≠ Elo: SxS is labeled for audits; only anonymous battles change ratings (see: [2], plus the official [3]).
- Repo-aware surprises: average overall models can win in RepoChat on your codebase (especially if your workflow depends on repo-aware code assistants).
- Latency matters: ask raters to flag when answers are “too slow to be useful.”
Caveats & privacy
- Human preference ≠ ground truth. Treat Elo as one signal; verify with your tests/benchmarks.
- Small Elo deltas are noisy. Break ties with your own prompts.
- Privacy: treat LMArena as public—don’t paste sensitive data, and review why inputs should be treated as untrusted (and effectively public).
Failure modes & Goodhart (how to not get fooled)
- Prompt-style bias: “polished” writing can beat correct-but-dry answers in preference voting.
- Verbosity bias: longer answers often “feel” better—even when they’re less precise.
- Rater variance: skill, patience, and domain knowledge vary wildly across voters.
- Domain mismatch: a model that wins general prompts can lose badly on your niche format, jargon, or constraints.
- Post-training artifacts: alignment, memorization, and “benchmark behavior” can move rankings without improving real-world reliability.
Don’t pick a single winner—pick a routing plan
Run 10–20 arena battles per task type, compare Overall + Category Elo with MT-Bench/MMLU, and keep a lightweight rubric (correctness, latency, citations/tool-use). If the top two are close, prefer the one that wins your failure cases. Then formalize the decision with a router-first blueprint for production routing. Re-check monthly; model drift is real.
Mini-template: 20-minute LMArena eval (copy/paste)
Goal
- Task(s):
- Constraints (latency, format, citations, tools):
Prompt set (6–8)
1.
2.
3.
Shortlist
- Model A:
- Model B:
- Model C:
Battles (10–20)
- Prompt #1: winner, why (notes)
- Prompt #2: winner, why (notes)
Operational notes
- Latency: (p50/p95 impressions)
- Formatting issues:
- Failure modes observed:
Ship decision
- Winner per task:
- Router rules (if any):
- Recheck date:
FAQ
Tip: Each question below expands to a concise, production-oriented answer.
What exactly is LMArena?
A public, anonymous, pairwise arena where humans vote on better answers; an Elo-style system turns those votes into a live leaderboard.
Is Elo just “who sounds nicer”?
It’s a preference signal. Use it with MT-Bench/MMLU and category filters to avoid style-over-substance traps.
Which model is #1 right now?
It changes. Check Overall, then your category; small Elo gaps are noise—validate on your prompts.
Are my prompts private?
Treat them as not private; don’t paste sensitive data.
Why do teams use LMArena?
To de-risk launches, route by task, detect regressions, tune prompts/guardrails, and validate cost–performance trade-offs on real prompts.
Is Elo reliable on its own?
It captures human preference, not ground truth. Triangulate with MT-Bench, MMLU, and category leaderboards, and validate on your prompts.
How do I add my model?
Follow FastChat’s How to add a new model (host your own/3rd-party API or request LMSYS hosting).
Is there recent open data I can analyze?
Yes—LMArena/LMSYS periodically releases open datasets. Starting points:
Elo gap is small and confidence intervals overlap
Treat as a tie; break with your prompts and failure cases.
You deploy across heterogeneous tasks
Route by task using category leaderboards + targeted battles.
You handle sensitive data
Do not paste prompts; treat Arena as public.
Updates: Updated on Feb 21, 2026 • v1.1ShowHide
- Updated Text/Coding/WebDev leaderboard snapshot tables and labels (as of Feb 19-21, 2026).
- Aligned external references to arena.ai leaderboard URLs and refreshed `asOf`/`updatedAt`.
- Added contextual internal links for routing, evaluation pitfalls, security, retrieval basics, and code assistants.
Older updates
- Published the first version of the LMArena guide.




