

What is Mixture of Experts (MoE)? The Secret Behind Efficient AI Models
FREE1. Introduction: The Dilemma of AI Scaling
Imagine an AI model as a massive brain, processing language with human-like precision. But there’s a catch—every time we scale these models for better accuracy, we also multiply their computational cost. What if we could have both power and efficiency?
🚀 Enter Mixture of Experts (MoE)—a game-changing architecture that activates only the necessary parts of a model, reducing computational cost without sacrificing intelligence.
Traditional deep learning models rely on dense architectures, where every neuron works on every input. This brute-force approach is powerful but unsustainable for scaling large language models (LLMs) like GPT-4. MoE changes the game by making AI smarter, not just bigger.
2. The Core Architecture of Mixture of Experts (MoE)
How MoE Works: A Smarter Way to Process Information
Unlike standard models that process every input with all their neurons, MoE activates only a subset of its neural networks—called experts—for each input.
🔹 Key Component: The Gating Network
Instead of treating all data equally, MoE employs a gating network to decide which few experts should process each token of input.
- Think of it like a university: You don’t send every student to every professor. Instead, a guidance system directs students to the most relevant subject-matter experts.
🔹 Mathematical Formulation
At its core, MoE can be expressed as:
y = Σᵢⁱᴺ G(x)ᵢ Eᵢ(x)
where:
- ( G(x) ) is the gating function, which assigns input to the best expert(s).
- ( E_i(x) ) represents the expert networks that handle the computation.
- The sum ensures that multiple experts contribute proportionally to the output.
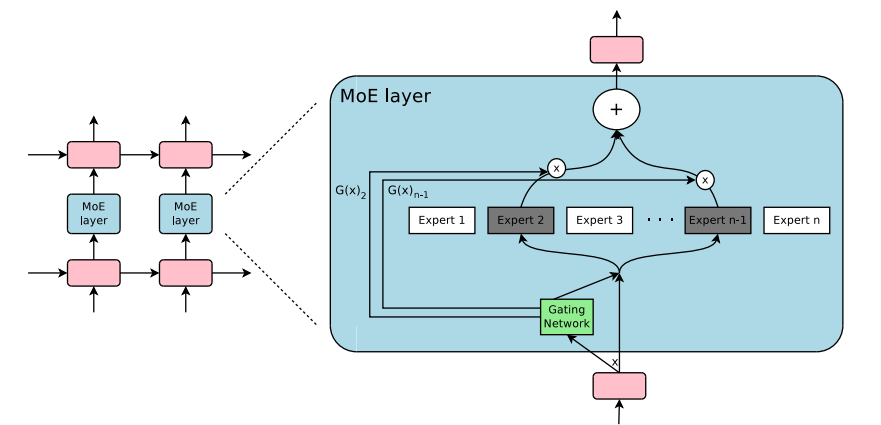 Image taken from Hugging Face
Image taken from Hugging Face
Comparison to Traditional Dense Models
| Feature | Dense Models | Mixture of Experts |
|---|---|---|
| Computational Load | All neurons process every input | Only a few experts activate per input |
| Scalability | High cost per scale | Efficient scaling with expert selection |
| Specialization | One-size-fits-all model | Different experts specialize in different tasks |
By allowing specialization, MoE improves performance while reducing computation costs, making it ideal for large-scale AI models.
3. Advantages and Trade-offs of MoE
✅ Why MoE is a Game-Changer
🔹 Computational Efficiency – Instead of overloading the entire model, MoE activates only relevant experts, reducing FLOPs (Floating Point Operations) per inference.
🔹 Better Scalability – Unlike traditional LLMs, which become exponentially more expensive to scale, MoE allows for larger models without increasing computational cost at the same rate.
🔹 Higher Model Capacity – More parameters can be added without inflating inference costs, meaning AI models can learn more without being computationally bloated.
⚠️ Challenges in MoE Models
❌ Load Balancing Issues – Some experts get used more frequently than others, leading to bottlenecks. If one expert is overwhelmed while others are underutilized, efficiency suffers.
❌ Training Instability – The gating function can favor certain experts disproportionately, causing others to collapse or become redundant.
❌ Communication Overhead – In multi-GPU setups, transferring data between different experts increases latency, requiring advanced parallelization techniques.
Despite these challenges, MoE has proven to be the most promising approach for efficiently scaling AI.
4. Real-World MoE Implementations in LLMs
Here’s how leading AI models are leveraging MoE to revolutionize efficiency:
| Model | Number of Experts | Experts Activated | Key Features |
|---|---|---|---|
| DeepSeek-MoE | 64 | 2 | Open-source, efficient routing |
| Switch Transformer (Google) | 32 | 1 | First large-scale MoE model |
| GLaM (Google) | 64 | 2 | High accuracy, lower training cost |
| Mixtral (Mistral AI) | 8 | 2 | Stability & fast inference |
| AlexaTM 20B (Amazon) | 16 | 2 | Optimized for real-world NLP |
🔍 DeepSeek-MoE: A Closer Look
Among modern MoE models, DeepSeek-MoE stands out as one of the most efficient open-source implementations.
- Uses 64 experts, but activates only 2 per token → Lower computational cost, high efficiency.
- Designed to minimize expert imbalance, solving a critical weakness in earlier MoE models.
- Competes with dense models like GPT-4, but at significantly lower training cost.
📌 Real-World Applications of MoE
✅ High-performance NLP → Faster, cheaper large-scale text generation.
✅ Efficient deployment → Reduces inference costs for production AI applications.
✅ Custom AI Solutions → Fine-tuned for domain-specific tasks like legal, medical, or financial AI.
5. The Future of MoE in AI Research & Development
🔮 Next-Gen MoE Innovations:
🚀 Hierarchical MoE: Multi-layered expert selection for deeper specialization.
🚀 Dynamic Expert Pruning: AI models can drop unused experts automatically to improve efficiency.
🚀 Hybrid MoE & Sparse Models: Combining MoE with retrieval-augmented generation (RAG) to improve factual accuracy in LLMs.
🌎 MoE Will Shape the Future of AI Scaling
With computational costs becoming the biggest bottleneck for scaling AI, Mixture of Experts is not just an option—it’s a necessity. Companies and researchers are already shifting toward MoE-powered architectures to balance cost, efficiency, and intelligence.
6. Conclusion & Call to Action
Mixture of Experts is revolutionizing AI, making models smarter, faster, and more cost-efficient.
If you’re an AI researcher, explore DeepSeek-MoE’s open-source implementation. If you’re a developer, try implementing MoE layers in PyTorch or TensorFlow to experience the benefits firsthand.




