
Introduzione alla classificazione nel Machine Learning
FREELa classificazione ha l’obiettivo di andare a identificare (e quindi classificare) a quale categoria appartiene un elemento che viene dato in input, tutto ciò tramite un algoritmo (o modello) di classificazione che riesce a capire, in maniera automatica, l’appartenenza alla categoria dell’elemento interessato.
Che cosa è la Classificazione?
La classificazione è un processo che consiste nel creare un modello che possa essere usato per descrivere un insieme di elementi.
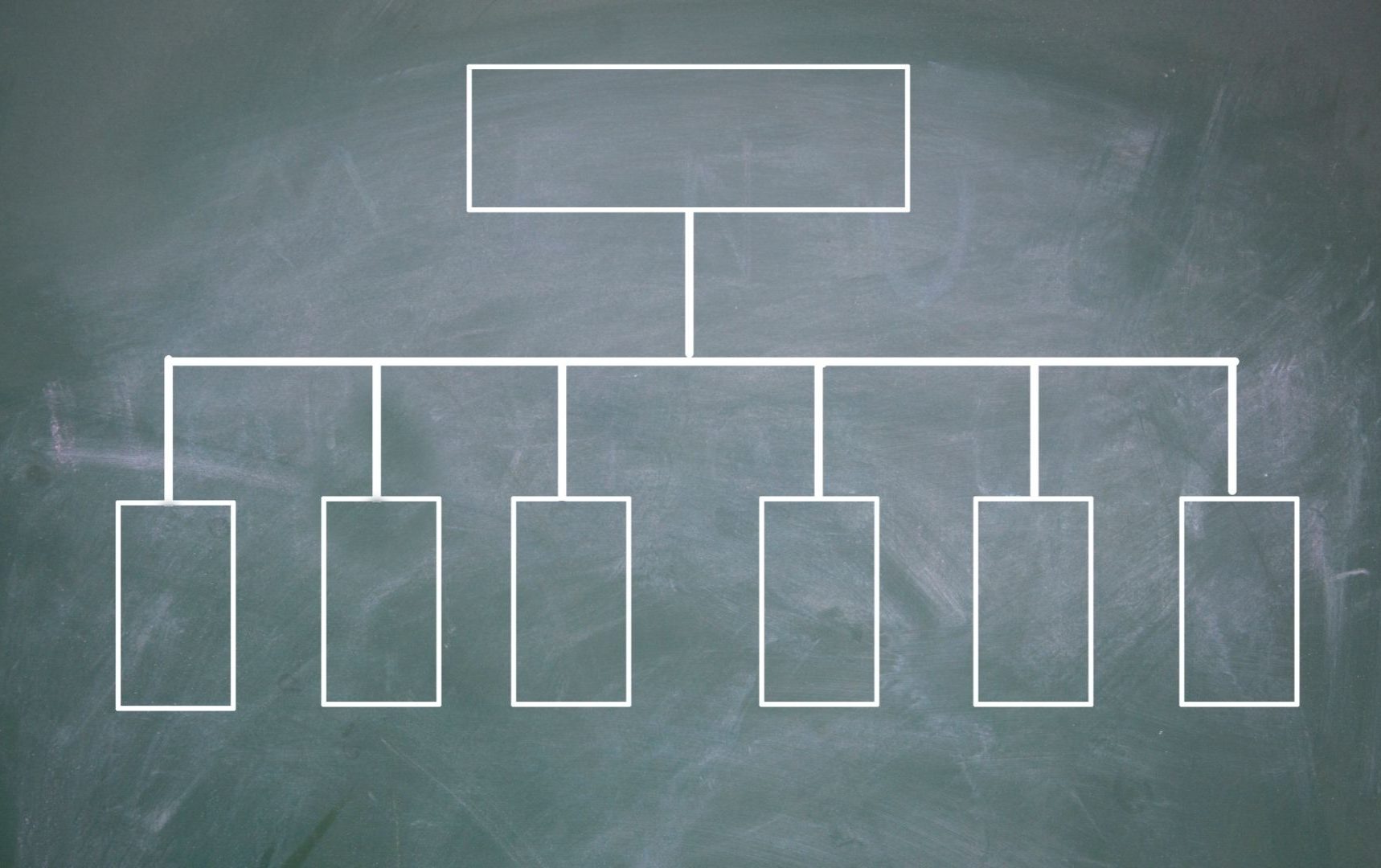
Sostanzialmente, ogni elemento viene classificato con una classe che lo identifica. Nell’esempio sottostante, vogliamo capire a quale delle cinque classi appartenga un elemento dato in input.
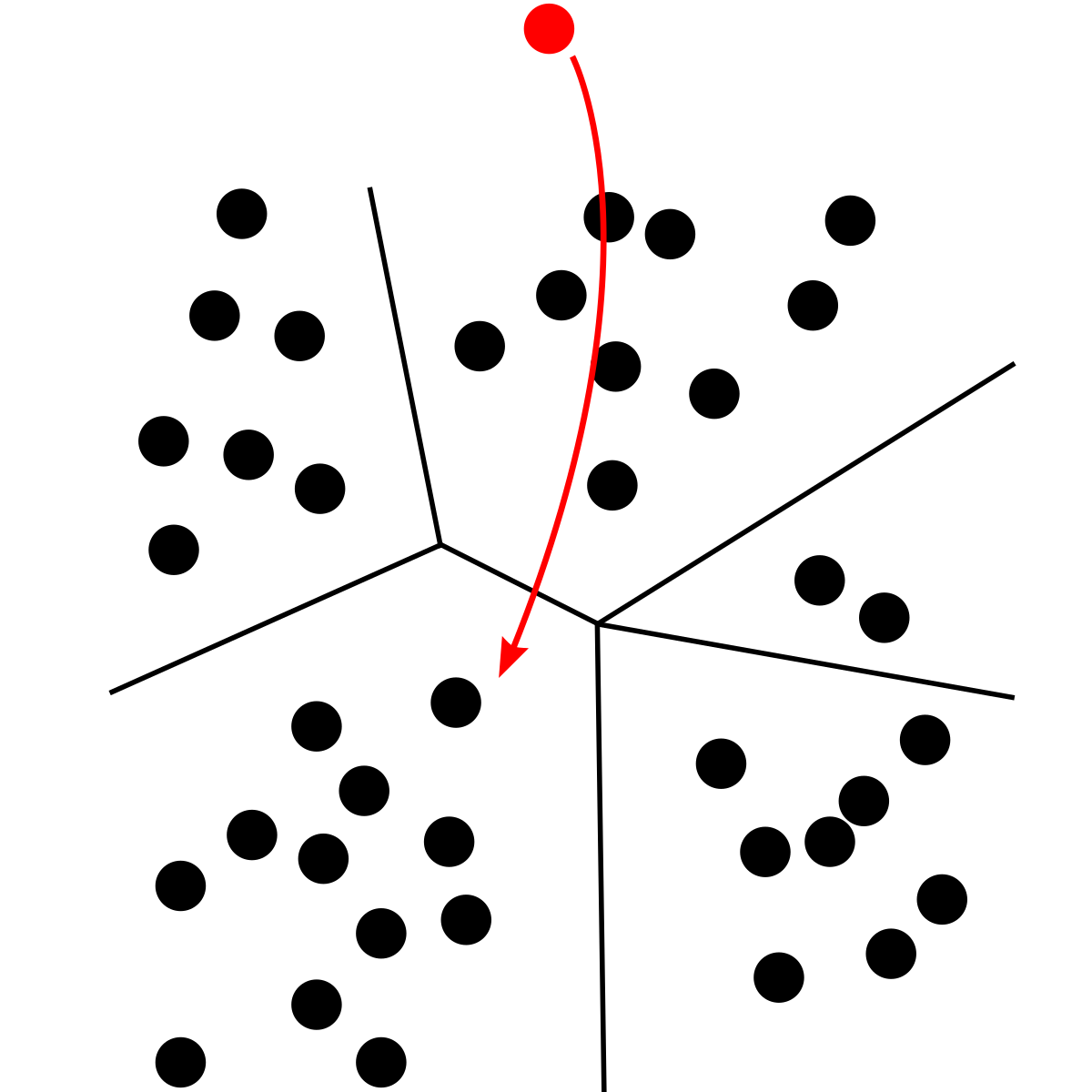 |
|---|
| Esempio di classificazione con 5 classi. |
Un esempio ancora più pratico sono le email che riceviamo: un algoritmo, ogni volta che riceviamo una mail, la analizza e la etichetta come spam o non spam; in base a delle regole apprese dall’esperienza della macchina durante una fase detta “fase di addestramento” (come ad esempio: la presenza di link all’interno della mail, la presenza di allegati, l’indirizzo email di chi ci invia la mail). In questo caso le classi sono solo due appunto: spam e non-spam.
Come funziona la Classificazione?
La classificazione può essere distinta in tre fasi diverse:
- Addestramento: ovvero si produce l’algoritmo (o il modello) che andrà a classificare appunto i nostri elementi di input. In questa fase vengono forniti anche un insieme di elementi già classificati. Questa fase si fa affinché l’algoritmo possa capire, analizzando i dati già classificati, le caratteristiche più importati che legano l’elemento alla classe in cui è stato categorizzato. Questo approccio, ovvero quello in cui forniamo dei dati già classificati, è detto apprendimento supervisionato.
- Test dell’accuratezza: dopo la prima fase in cui il modello ha studiato, arriva il momento di interrogarlo. Si effettuano una serie di test su un insieme detto appunto test set. Questo insieme differisce dall’insieme dato al modello durante la fase di addestramento. Effettuati i test, si controllano le percentuali di errore
- Utilizzo del modello: corrisponde alla messa in atto del modello che abbiamo costruito con le due fasi precedenti, quindi vengono dati in input elementi senza alcuna classificazione e sta al modello classificare ogni elemento.
Un caso particolare di classificazione è quella in cui l’addestramento viene fatto in maniera non supervisionata, ovvero non vengono forniti esempi già classificati al nostro modello; che in mancanza di essi si basa sulla vicinanza/distanza dei dati. Ad esempio, se i dati di una mail sono simili a quella di una mail in spam, allora anche la prima mail verrà classificata come tale. E viceversa.
Quali sono le applicazioni della Classificazione?
La classificazione è usata ampiamente in molti ambiti, un esempio molto classico è la classificazione scientifica che i biologi usano per raggruppare le specie di organismi viventi e fossili: vale a dire riunirli in categorie in base a quello che hanno in comune, appunto.
Un altro esempio molto diffuso è la classificazione nel regno animale, quindi capire a quale famiglia appartiene una determinata specie.
Un esempio di classificazione molto conosciuto è quello della tavola periodica: infatti in essa, gli elementi sono raggruppati in base al tipo di orbitale atomico che viene riempito.
FONTI: