

LEANN: Local-First RAG With 50× Less Storage (No Dense Matrix)
FREEDevelopers and AI engineers building production-ready local-first applications where privacy and storage footprint are critical constraints.
A retrieval method where semantic structure is stored as edges between chunks in a graph, allowing original embeddings to be discarded and only recomputed for a small subset of relevant nodes during query-time traversal.
Local RAG Without Persisting Full Embeddings
Discard the dense vector matrix post-build to minimize storage; selective query-time recomputation preserves speed without the bulk.
Non-obvious insight: you can delete the dense embedding matrix after index build, the graph preserves neighborhood structure (with PQ codes + selective recompute).
Paper reports ~10% end-to-end overhead on RAG workloads in their specific evaluation setup while achieving up to ~50× smaller storage.
Best fit: privacy-first, storage-constrained local knowledge bases (laptop/edge).
Not best fit: high-QPS / ultra-low-latency or rapidly changing corpora with heavy incremental updates.
Production rule: treat retrieved text as untrusted input; local-first reduces exposure surface but doesn’t eliminate prompt-injection risks.
The biggest hidden cost in local RAG often isn’t the inference, it’s persisting the dense embedding matrix. LEANN (a low-storage vector index) shows a different path: build a graph using embeddings once, then drop the dense matrix and selectively recompute only what you need at query time.
Technical note: LEANN doesn’t store the full embedding matrix; it persists a compact structure (a pruned proximity graph + PQ codes) to route queries efficiently [1].
Can You Really Delete Your Vector Database?
To be precise: you still need a vector index (graph + PQ), but you don’t need to persist the dense embedding matrix.

For developers building local-first applications, the "hidden tax" is storage footprint. A typical corpus can easily result in an embedding index larger than the documents themselves. If you're building for a laptop or an edge device, this is a real constraint.
The core insight from the LEANN paper [1] is that structure > vectors. A proximity graph like HNSW (Hierarchical Navigable Small World) [3] encodes semantic relationships in its edges. Once that graph is built, the original high-dimensional vectors are mostly redundant, they served to define the neighborhood, but the graph is the neighborhood. More precisely: the topology preserves neighbor relationships; PQ provides cheap approximate distances, and recomputation reranks a small candidate set.
By discarding the dense matrix and using Product Quantization (PQ) for initial routing, you can cut storage by up to ~50× while only adding a ~10% latency overhead [1].
Key Takeaway: Stop worrying about how to compress your vector database and start asking if you need to store it at all. In local environments, recomputing a few embeddings on-the-fly is often faster than reading a massive matrix from disk.
Why Local-First RAG Demands a New Architecture

Building RAG (Retrieval-Augmented Generation) for the cloud is about scaling QPS; building it for local devices is about scarcity management. This shift in focus is why Router-first RAG architectures are gaining traction in local-first designs.
The Privacy and Data Exposure Win
Keeping the index local isn't just a performance choice; it's a security guardrail. By avoiding third-party vector DBs and cloud logs, you shrink the exposure surface of sensitive documents.
The Bottleneck Shift: Disk I/O vs. GPU
In cloud environments, optimization typically focuses on compute density. On a local device, storage I/O is frequently the bottleneck. Loading a multi-gigabyte embedding matrix into RAM or swapping it from disk kills the user experience. By trading a tiny bit of CPU/GPU throughput for a massive reduction in I/O, LEANN aligns with the strengths of modern local hardware.
How LEANN Works: The Pipeline Walkthrough

The LEANN pipeline is a clean example of lazy evaluation. Instead of preparing everything in advance, it builds a structural map and waits for the query to define what's relevant.
- Ingestion & Normalization: Standard text chunking, perhaps slightly coarser to reduce graph nodes.
- Temporary Embedding: You still need embeddings to build the graph, but they are transient.
- Graph Construction: Build any proximity graph (like HNSW - Hierarchical Navigable Small World). This is where semantic knowledge is "baked" into topology.
- The Purge: Delete the dense embedding matrix. This is the moment you reclaim your disk space.
- Query-Time Selective Recompute:
- Compute the query embedding.
- Traverse the graph using PQ codes for first-pass similarity.
- For the most promising candidates, recompute their original embeddings using the local encoder model.
- Rank these few candidates and assemble the context.
Why recompute isn't slow
Selective recomputation is only viable because of the proximity graph. You aren't recomputing the world, you are recomputing the neighborhood. Modern local encoders are often fast enough in many local setups to re-embed a dozen chunks in milliseconds, which is often negligible compared to the time the LLM takes to generate a response.
Evidence that Matters
Across standard benchmarks, the researchers report results that challenge the "always persist" dogma:
- Index size: <5% of raw data (up to 50× smaller than standard dense indexes) [1].
- Recall target: ~90% Top-3 recall on standard datasets [1].
- Latency target: Under 2 seconds end-to-end (Setup: QA benchmark on consumer hardware) [1].
- What’s persisted: Pruned graph adjacency lists + PQ code table [1].
Decision Matrix: When to Delete Your Embeddings
| Constraint | Classic Vector Store | Compressed (PQ/Quant) | LEANN (Recompute) | Why |
|---|---|---|---|---|
| Storage | ❌ High | ⚠️ Medium | ✅ Ultra-Low | LEANN drops the matrix entirely. |
| Latency | ✅ Ultra-Low | ✅ Low | ⚠️ Moderate | Selective recompute adds overhead. |
| QPS | ✅ Very High | ✅ High | ⚠️ Moderate | Heavy traffic is CPU-bound. |
| Complexity | ✅ Low | ⚠️ Medium | ❌ High | Requires custom graph/recompute logic. |
| Privacy | ⚠️ Service-dependent | ✅ On-device possible | ✅ Strong (Local-First) | No external vector DB required; privacy still depends on your embedding/LLM runtime choices. |
For most internal knowledge bases or on-device assistants like those powered by systems like Claude Code and MCP, LEANN is a superior design pattern.
Playbook: What to cache in a LEANN-style system
If you're implementing this architecture, caching is your best friend for masking recompute latency (read also the deep dive with RAGCache):
- Traversal results: Cache traversal results for frequent queries (or query embeddings) to skip graph walking.
- Candidate sets: Cache candidate sets or top-K nodes per query cluster.
- Embedding hot-nodes: Keep the dense vectors for the top 1% most visited nodes in RAM.
- Similarity results: A simple LRU cache for exact query matches.
- Warm-up phase: Pre-compute embeddings for a "root set" of entry nodes on startup.
- Hardware batches: Group recompute requests to leverage SIMD/GPU parallelism efficiently.
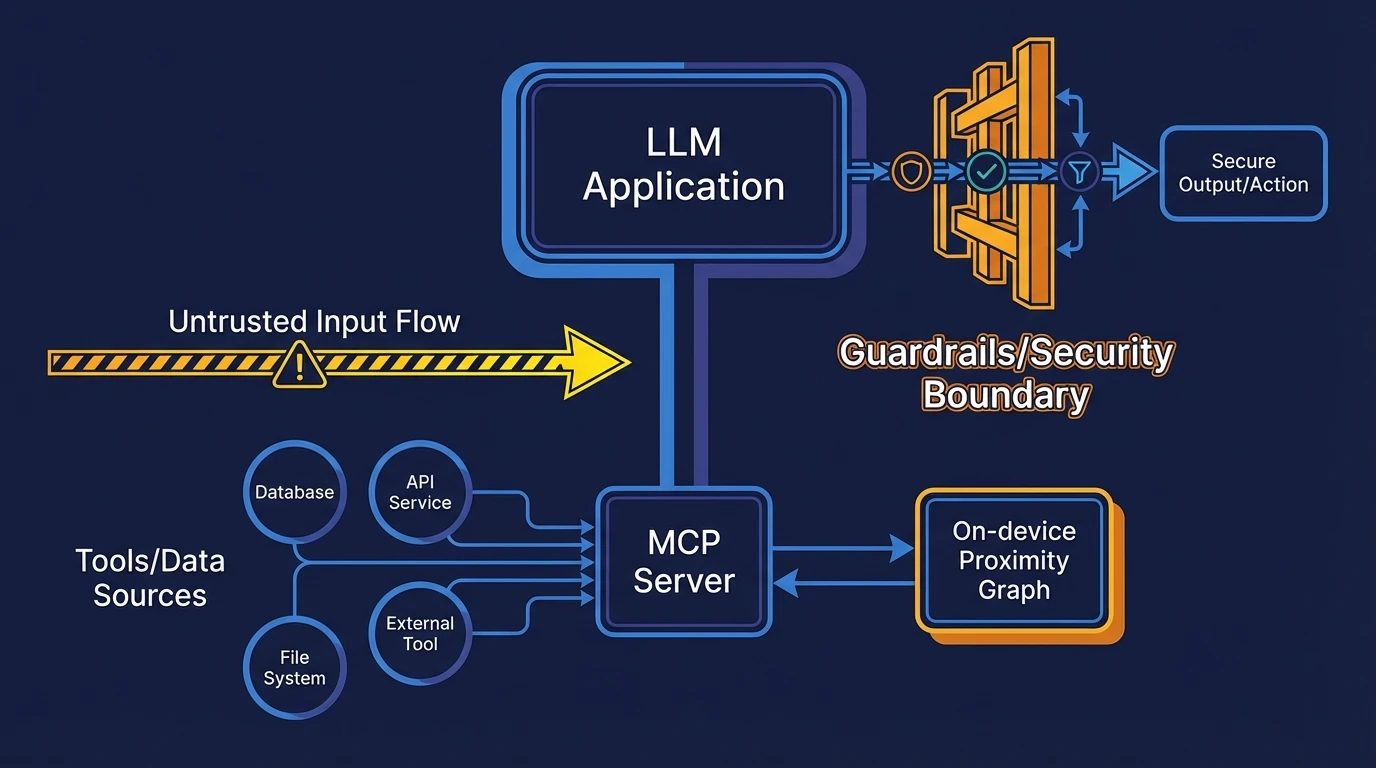
Authority & Deployment: Using MCP and Local Backends

To move from paper to production, you need a standardized bridge. The Model Context Protocol (MCP) is a JSON-RPC protocol to plug an LLM app into tools/data sources via standardized servers [4]. In a LEANN setup, the MCP server acts as the coordinator between the on-device proximity graph and the LLM.
Security: Reducing the Exposure Surface
Always treat retrieved text as untrusted input. According to the OWASP Top 10 for LLM Applications, Prompt Injection is the #1 risk [5]. While local-first architectures significantly reduce the data exposure surface (privacy), they do not remove the trust boundary requirement. You must still implement robust output validation using dedicated Guardrails.
Limitations: The Reality Check
No architecture is a silver bullet. You must account for:
- Embedding Drift: If you update your model, you must rebuild the graph. Structure is tied to the specific "view" of the world your encoder provides.
- Dynamic Corpora: If your data changes every 5 seconds, the overhead of structural graph maintenance might outweigh the storage wins.
- Hardware Pinning: Optimal performance assumes you have at least some acceleration (SIMD on CPU or a mobile GPU) for the selective recompute phase.
FAQ
Do you still need a vector database for RAG?
No, not in the traditional sense. LEANN replaces the massive embedding matrix with a compact proximity graph and PQ codes. You still need an index (the graph), but you don't need to persist the high-dimensional vectors that usually drive up storage costs.
Is recomputing embeddings at query time always viable?
It works best when your hardware supports efficient inference (SIMD/GPU) and your retrieval budget allows for small overhead. LEANN minimizes this by using a graph to only recompute embeddings for the chunks most likely to be relevant, rather than the whole corpus.
What happens if I switch embedding models?
Since the proximity graph is built based on the relationships defined by a specific model, switching models requires rebuilding the graph. In a local-first setup, you should pin your encoder version to ensure retrieval consistency.
How does this compare to compressed vector stores (PQ/quantization)?
Standard compression (like Product Quantization) reduces the size of each vector but still stores them all. LEANN uses PQ for the initial graph build but then discards the dense vectors entirely, relying on the graph structure and selective recompute to find matches.
Is local-first automatically secure?
Local-first prevents your data from leaving the device, which is a massive privacy win. However, it doesn't solve prompt injection—you must still treat any retrieved text as untrusted context before feeding it to your LLM.
References
Embedding Drift
Pin encoder versions and implement a clear rebuild lifecycle for model updates.
Incremental Update Friction
Batch updates or schedule periodic full rebuilds if the corpus is not hyper-dynamic.
Cold-Start Latency
Implement hot-path caching for frequent queries and use hardware acceleration (SIMD/GPU).




