

GenAI Roadmap 2026: Enterprise Agents & Practical Playbook
FREEBusiness leaders, AI practitioners and students seeking a strategic roadmap and practical playbook for enterprise AI agents in 2026.
Autonomous systems designed to pursue specific business goals within defined constraints, capable of sensing, reasoning, acting, and self-correcting. They represent a shift from reactive AI assistants to proactive, goal-driven automation engines.
GenAI in 2026: Embracing Enterprise Agents
Prioritize building robust agent architectures with RAG for reliable, goal-driven automation rather than focusing solely on conversational LLM capabilities.
By 2026, up to 40% of enterprise applications will include task-specific AI agents, shifting from chatbots to workflow execution (Gartner).
But: over 40% of agentic AI projects may be canceled by end of 2027 due to cost, unclear value, or weak risk controls (Gartner).
Enterprise AI agents automate workflows by sensing, reasoning, acting, and self-correcting.
Reliability in agents is engineered through deterministic scaffolding and RAG architectures, not solely LLM power.
RAG can reduce hallucinations in knowledge-intensive tasks by grounding outputs in retrieved evidence (but only if retrieval quality is high).
Agents pursue goals within constraints, while assistants merely respond to prompts.
By 2026, up to 40% of enterprise applications will include task-specific AI agents, shifting from chatbots to workflow execution [1]. But over 40% of those projects may be canceled by end of 2027 due to cost, unclear value, or weak risk controls [2]. This article gives midway AI enthusiasts and business users a practical playbook to navigate this shift—and avoid the pitfalls that kill most enterprise agent initiatives.
Critical Success Factors for Enterprise Agents
- Don't just chat, execute: Focus on task-specific agents deeply embedded in apps (Gartner).
- Mitigate cancellation risk: >40% of projects will fail by 2027 without clear ROI and risk controls.
- Engineer your RAG: Retrieval quality is a system dependency, not a magic fix.
- Build scaffolding first: Prioritize schemas, permissions, and verification over raw LLM power.
- Govern from day one: Use the 30–60–90 playbook to move from pilot to audited production.
Why the 2026 GenAI roadmap shifts to enterprise AI agents

If your Generative AI roadmap for 2026 still revolves around building a better chatbot, you're planning for the past. The industry is shifting from conversational systems toward autonomous agents that sense, reason, act, and self-correct within business workflows [4].
Key Stat (adoption): By 2026, Gartner predicts up to 40% of enterprise applications will include integrated task-specific AI agents, up from less than 5% in 2025 [1].
Key Stat (failure risk): Gartner also predicts over 40% of agentic AI projects will be canceled by end of 2027 due to escalating costs, unclear business value, or inadequate risk controls [2].
The two stats together tell you the real story: the opportunity is large, but most teams will fail because they underestimate the engineering required. Standalone LLMs hallucinate facts, cannot access real-time or proprietary data, and are expensive to retrain [3]. Enterprises that need verifiable, goal-driven results must wrap those LLMs in purpose-built agent architectures—or face the 40%+ cancellation rate.
How Do LLMs and RAG Architectures Power Reliable Generative AI in 2026?

Standalone Large Language Models (LLMs) often lack access to real-time or proprietary enterprise data, leading to factual inconsistencies despite their articulation capabilities. They struggle with real-world enterprise needs, tend to hallucinate facts, and are prohibitively expensive to retrain with every new product update [5]. This is the core liability that has, until now, kept truly autonomous AI on the sidelines.
Enter Retrieval-Augmented Generation (RAG). Instead of relying solely on its static training data, a RAG architecture connects an LLM to your organization's specific, up-to-date knowledge. When a query comes in, the system first retrieves relevant documents from your internal data—like a knowledge base, product specs, or CRM notes—and then feeds this context to the LLM along with the original prompt. RAG can reduce ungrounded outputs in knowledge-intensive tasks when retrieval quality is high and evaluated [5].
The Strategic Shift from Raw Power to Grounded Reliability
RAG is a foundational pattern because it can improve factuality in knowledge-intensive tasks by grounding outputs in retrieved evidence [5]:
- Factual Accuracy: Responses are based on your documents, not the LLM's generic knowledge.
- Up-to-Date Knowledge: The system's intelligence evolves as you update your documents, no costly retraining required.
- Proprietary Customization: The AI can reason about your specific products, customers, and processes.
RAG Reality Check: 3 Failure Modes You Must Engineer Against
RAG is not magic. Teams fail when they treat “retrieval” as a checkbox instead of a system with measurable quality [5]:
Bad retrieval → confident wrong answers
If top-k is irrelevant, the model becomes a fluent rationalizer.Context overload → lost-in-the-middle
Too much unranked evidence dilutes attention and harms accuracy.No citations / no verification → no auditability
If you can’t show evidence, you can’t govern outcomes.
Key Takeaway: Use RAG to ground outputs, but treat retrieval quality (ranking, chunking, evaluation) as an engineered component—not a feature toggle.
This architectural choice is what makes sophisticated tools like context-aware AI code assistants possible. It's the engineering that ensures the 40% of enterprise applications using agents by 2026 will be reliable enough for real work [1].
Key Takeaway: RAG is the essential architectural foundation ensuring enterprise agent trustworthiness. It shifts the focus from the LLM's raw intelligence to the quality and relevance of the data it can access.
What are Enterprise AI Agents and Why are They Central to the Future of GenAI?

Operational definition. By "enterprise AI agent" we mean a software system that (1) receives a goal rather than a single prompt, (2) plans a sequence of actions, (3) executes those actions via tools or APIs with scoped permissions, (4) evaluates the outcome, and (5) self-corrects—all within policy-defined guardrails. This is fundamentally different from an assistant, which executes one prompt → one response [4]. To learn more, it's useful to explore the key differences between Agentic AI and Traditional AI.
Reliability is Engineered, Not Assumed
The reliability of an enterprise agent doesn't come from the raw power of the LLM. It comes from the deterministic scaffolding around it [4]: schema validation on outputs, least-privilege tool permissions, retry policies, and human-in-the-loop gates. The architecture enables a continuous cycle—sense → reason → act → verify—where each step has explicit contracts and fallbacks.
Minimum Viable Enterprise Agent Stack (Copy/Paste)
If you want “enterprise-grade” results, you need an enterprise-grade stack. Here’s a minimum blueprint:
- Orchestrator / Agent loop: plan → act → verify → learn
- Tools + permissions: least-privilege scopes, rate limits, approvals
- Knowledge layer (RAG): retrieval + ranking + evidence packaging
- Output contracts: structured outputs (JSON/schema) for tool calls
- Verification: validations, guardrails, retries, safe fallbacks
- Observability: traces, logs, tool error rate, cost + latency
- Governance: policies, audit trails, human-in-the-loop gates
This is the difference between a demo and a system you can run in production.
Example Workflow: Autonomous Invoice Exception Handling
To move beyond theory, here is a concrete end-to-end agentic workflow for Finance:
- Trigger: New invoice received with status "Mismatch".
- Orchestrator: Agent analyzes the mismatch reason (e.g., "PO amount differs").
- Tool Use (Retrieval): Fetches original Purchase Order (PO) and email thread with vendor.
- Reasoning: Compares Invoice vs. PO. Identifies a pre-approved variance in the email thread.
- Action (Gated): If variance < $50, auto-approve; if > $50, draft Slack message to Manager for approval.
- Verification: Validates that the update was logged in the ERP.
KPIs for this workflow:
- Touchless Resolution Rate: % of exceptions solved without humans.
- Accuracy: 0 false positives on auto-approvals (enforced by audit).
Field Note: When the Agent Stack is Missing Layers
In a mid-2025 internal pilot, we tested an LLM-based agent for triaging inbound support tickets. The agent used a RAG pipeline over a Confluence knowledge base and could call Jira APIs to create, label, and assign tickets. The first prototype looked impressive in demos—correct routing ~85% of the time on a golden set.
In production, three things failed that the demo hid:
- Permission sprawl: the agent had write access to all Jira projects. A malformed tool call moved 12 tickets to the wrong board in one batch. We learned to scope tool permissions per-project with explicit allow-lists.
- Retrieval drift: after two weeks, the knowledge base had new articles but the embedding index was stale. The agent started hallucinating labels because top-k results were irrelevant. We added a nightly re-index job and a retrieval-quality smoke test that blocks deploys if recall drops below 0.7 on a golden set.
- No structured output contract: the agent returned free-text labels instead of enum values, which broke downstream automations. Adding a JSON schema contract with retry-on-validation-error solved it.
None of these problems came from the LLM itself. They came from missing layers in the stack—exactly the layers listed above.
When NOT to Use Agents
Agents add complexity. Before committing, check whether the cost is justified:
- Simple, deterministic workflows: If the logic is a flowchart with no ambiguity, a rules engine or a simple script is cheaper to build, debug, and maintain.
- Low-volume tasks: If the workflow runs 10 times/month, the engineering cost of building an agentic stack (orchestrator, tool permissions, observability, guardrails) will likely exceed the cost of a human doing the work.
- No tolerance for errors: In safety-critical domains where any wrong action is unacceptable (e.g., medication dosing), the probabilistic nature of LLM reasoning makes agents a poor fit without extremely expensive verification layers.
- Data isn't ready: If your knowledge base is unstructured, outdated, or undocumented, the RAG layer will fail—and the agent will fail with it. Fix the data first.
Key Takeaway: Agent architectures pay off when workflows are high-volume, semi-structured, and tolerant of gated automation. If those conditions aren't met, simpler solutions outperform agents on cost and reliability.
How to Effectively Evaluate and Govern Generative AI Agents in 2026?

Deploying autonomous agents without evaluation and governance is a fast path to expensive rollbacks. Success depends on two pillars: quantifiable evaluation tied to business outcomes, and governance that makes every agent action auditable.
First, evaluation must shift from academic benchmarks to business outcomes. For any agent to be considered reliable, you need to track concrete metrics:
- Task Completion Rate: What percentage of assigned tasks (e.g., resolving a support ticket, processing an invoice) does the agent complete successfully without human intervention?
- Hallucination Rate: How often does the agent invent facts or take actions based on incorrect information? This must be near zero for critical workflows.
- Response Latency: How quickly does the agent act? Response latency is critical but must not compromise accuracy.
Second, governance provides the essential guardrails. Governance extends beyond security to encompass operational predictability. A solid governance framework includes clear policy definitions (what an agent can and cannot do), complete audit trails for every action, and well-defined human-in-the-loop checkpoints for high-stakes decisions.
The 4-Layer Enterprise Control Model (Practical)
Use a layered control model aligned with widely used AI risk management practices:
Offline evaluation
Golden tasks + failure taxonomy + regression tests before release.Online monitoring
Drift, tool error rate, retrieval quality metrics, cost/latency budgets, escalation triggers.Safety gates
HITL approvals for high-stakes actions, least-privilege tool access, rate limits.Auditability
End-to-end tracing of: prompt/context → retrieved evidence → tool calls → outputs.
For a governance baseline, use NIST AI RMF and the Generative AI Profile as a practical checklist for risks and controls [6] [7].
Key Takeaway: If you can’t measure it and audit it, you can’t scale it. Agent reliability is as much an ops problem as it is a model problem.
What 'False Friends' and Common Pitfalls Threaten Your Generative AI Roadmap?

In developing your Generative AI roadmap for 2026, identify and mitigate 'false friends'—deceptive concepts that hinder progress. The most common is relying on 'zero-shot magic,' the idea that a powerful LLM can solve complex business problems with no structural support. In reality, enterprise-grade agents require engineered reliability, not just clever prompts.
Don't let buzzwords distract you from the real work. A growing risk is “agent washing”—rebranding chatbots as agents without real autonomy or controls, which inflates expectations and accelerates failed pilots [3].
The most common agent failures don't stem from the LLM, but from weak RAG pipelines, missing policy definitions, unstructured workflows, and a lack of observability. Prioritizing a chatbot's conversational polish over reliable data access and action controls will result in an architecturally obsolete system.
Key Takeaway: The biggest pitfall is mistaking conversational polish for operational readiness. True value comes from agentic systems that can autonomously and reliably execute tasks, which is a function of architecture, not just the underlying model.
Building Your 2026 Generative AI Roadmap: A Role-Based 30-60-90 Day Playbook
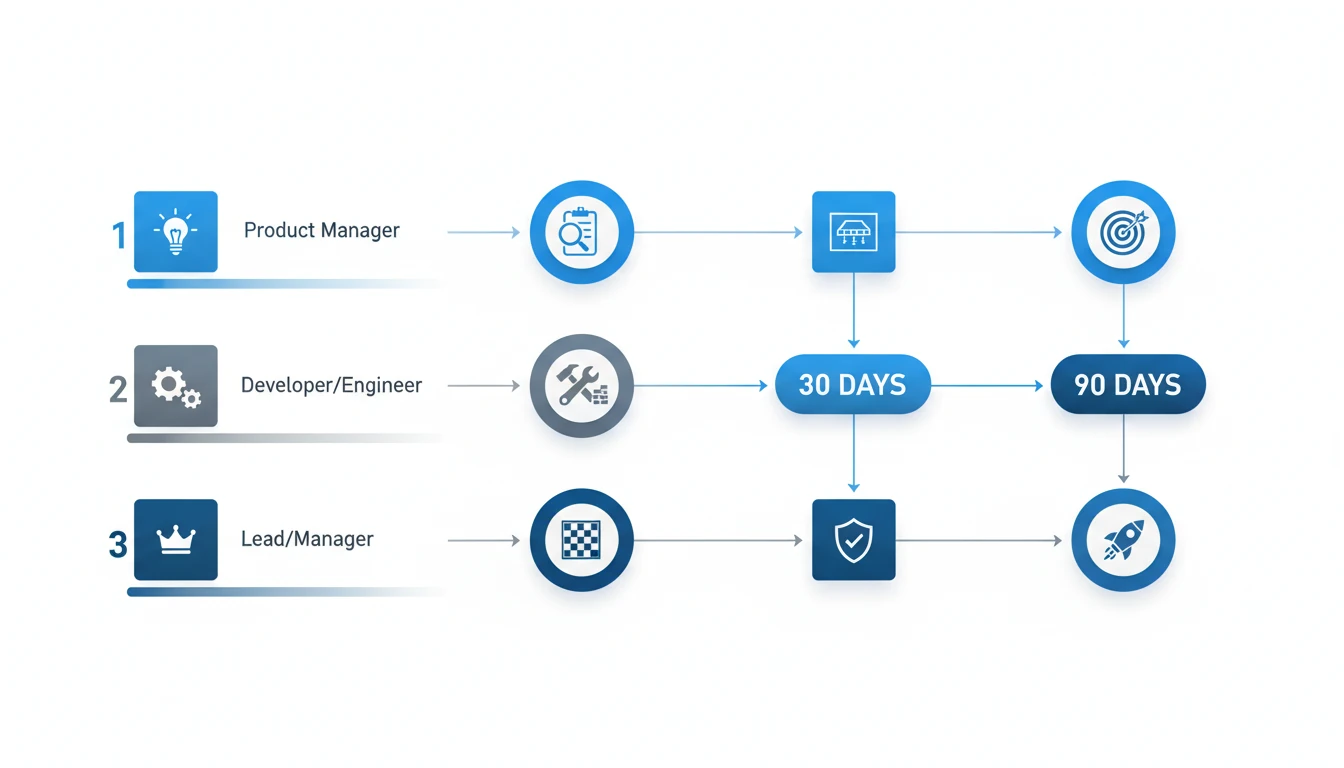
Effective execution is paramount for realizing a strategic vision. This playbook breaks down the agent-centric shift into a practical Generative AI roadmap 2026 tailored to your role. Instead of abstract goals, here are concrete actions to take in the next 90 days to prepare for the new landscape.
For Product Managers: Identify Value
Product Managers must identify critical enterprise pain points amenable to autonomous agent solutions, focusing on workflow automation over superficial feature addition.
- Days 1-30: Map a high-value, repetitive enterprise workflow. Identify 3-5 pain points where an agent could automate tasks or decisions. Define success KPIs (e.g., reduction in manual data entry or average resolution time—target values depend on your baseline).
- Days 31-60: Prototype a low-fidelity agent workflow for the top use case. Focus on the decision logic and data sources required. Gather early feedback from pilot users.
- Days 61-90: Develop a detailed requirements document. Define the agent’s operational boundaries, evaluation criteria, and governance policies.
For Developers & Engineers: Build Reliability
Your focus is on building the deterministic scaffolding that makes agents trustworthy [2]. The underlying LLM is merely one component of a production-grade agent.
- Days 1-30: Set up a RAG development environment. Ingest a small, clean dataset into a vector database and implement a basic retrieval pipeline [1].
- Days 31-60: Develop the agent's core logic. Integrate with one or two essential APIs (e.g., Jira, Salesforce) and implement robust logging for observability.
- Days 61-90: Implement strict guardrails and error handling. Refine the RAG pipeline for accuracy and conduct initial performance tests against the PM's KPIs.
For Leads & Managers: Enable the Shift
Leaders and Managers must cultivate an organizational environment conducive to agentic AI success, emphasizing robust governance and strategic alignment.
- Days 1-30: Educate your team on the shift from assistants to agents [5]. Identify and map skills gaps in areas like RAG architecture and agent evaluation.
- Days 31-60: Establish a clear governance framework for a pilot project. Define ethical guidelines, data handling policies, and allocate resources.
- Days 61-90: Closely monitor the pilot project's progress. Use the learnings to build a broader upskilling plan and integrate the agent strategy into your 2026 technology roadmap.
As you plan your next steps, consider how these actions align with the essential skills for long-term career growth in the evolving AI landscape.
FAQ
Tip: Each question below expands to a concise, production-oriented answer with edge cases and failure modes not covered above.
Can I use agents for low-volume, high-stakes workflows?
It depends. If a workflow runs fewer than ~50 times/month and each error has significant consequences (financial, legal, reputational), the cost of building a full agent stack—orchestrator, tool permissions, guardrails, observability—often exceeds the cost of a human reviewer. A better pattern: use an LLM-assisted tool that drafts an action and queues it for human approval, rather than a fully autonomous agent. Reserve full autonomy for high-volume, lower-stakes tasks where gated fallbacks are acceptable.
What happens when RAG retrieval quality degrades over time?
This is one of the most common silent failures. When your knowledge base grows or changes, embedding indexes go stale, and top-k results drift toward irrelevant documents. The agent won't tell you—it will just generate confident wrong answers. Mitigations: (1) schedule re-indexing jobs, (2) add a retrieval-quality smoke test to your CI/CD pipeline that blocks deploys if recall drops below a threshold on a golden set, and (3) monitor retrieval hit-rate in production dashboards.
How do I know if my agent is "agent-washed" vs. genuinely agentic?
Apply a simple test: does the system pursue a multi-step goal with branching logic, or does it execute a single prompt → response? If removing the "agent" label changes nothing about the architecture, it's agent-washing. Genuine agents have: (1) a plan-act-verify loop, (2) tool calls with scoped permissions, (3) conditional branching based on intermediate results, and (4) a fallback/escalation path when confidence is low.
What's the minimum team and skill set needed to ship a production agent?
A minimal production agent typically needs: 1 engineer with LLM/RAG experience (retrieval pipeline, prompt engineering, evaluation), 1 backend engineer (API integrations, infrastructure, observability), and a PM or domain expert who owns the workflow and defines success KPIs. The most common failure mode is missing the domain expert—without clear workflow rules, agents can't be properly scoped or evaluated.
Should I build my own agent framework or use an existing one?
For most teams, start with an existing framework (e.g., LangGraph, CrewAI, or the Anthropic agent patterns) and customize. Building from scratch only makes sense if you have non-negotiable constraints on latency, security, or tool integration that existing frameworks can't meet. The hidden cost of building from scratch is maintaining the orchestration, retry, and observability layers—these are harder to get right than the LLM integration itself.
References
- Gartner predicts up to 40% of enterprise apps will include task-specific AI agents by 2026 (press release, Aug 26 2025)
- Gartner predicts over 40% of agentic AI projects will be canceled by end of 2027 (press release, Jun 25 2025)
- Reuters: “agent washing” and why 40%+ projects may be scrapped by 2027 (Jun 25 2025)
- Anthropic: Building Effective AI Agents (Dec 19 2024)
- Retrieval-Augmented Generation for Large Language Models: A Survey (Gao et al., arXiv 2312.10997)
- NIST AI Risk Management Framework (AI RMF 1.0)
- NIST AI 600-1: Generative AI Profile (July 2024)
Goal is to move beyond basic information retrieval and towards autonomous task execution
Prioritize developing enterprise AI agents over conversational chatbots.
Need for reliable, factual outputs grounded in proprietary data
Implement Retrieval-Augmented Generation (RAG) architectures.
Concerned about AI hallucination and outdated information in enterprise applications
Leverage RAG to connect LLMs to external, verifiable data sources.
Aiming for truly autonomous AI capabilities in business systems
Focus on building deterministic scaffolding around LLMs to engineer agent reliability.
Relying on 'zero-shot magic' from powerful LLMs for complex business problems.
Focus on building engineered reliability through deterministic scaffolding and RAG architectures.
Shipping 'agentic' demos without a business case or controls.
Start from a measurable workflow KPI, add guardrails, and validate actions via audits and evals before scale.
Prioritizing chatbot conversational abilities over agentic task execution.
Understand that agents pursue goals autonomously, while assistants respond to prompts.
Weak RAG pipelines leading to agent failures.
Implement and rigorously test RAG pipelines for accuracy and data relevance.
Missing policy definitions and unstructured workflows.
Establish clear governance frameworks, policy definitions, and audit trails for agent actions.
Lack of observability in agent operations.
Implement robust logging and monitoring for agent actions and outcomes.




