Introduction to Information Retrieval Systems
FREEEssential data structures underlying IR systems
How does a search engine work? How is it possible to search through millions of documents and find just what the user was looking for? Welcome to the field of Information Retrieval!
The goal of an IR system is to satisfy the user\u2019s information needstarting from a large collection of documents.
We all know how to properly use a search engine. We type in our query, and if we don\u2019t like the results we modify the query until we find what we\u2019re looking for. We are then doing an iterative refinementof the query as shown in the following figure.
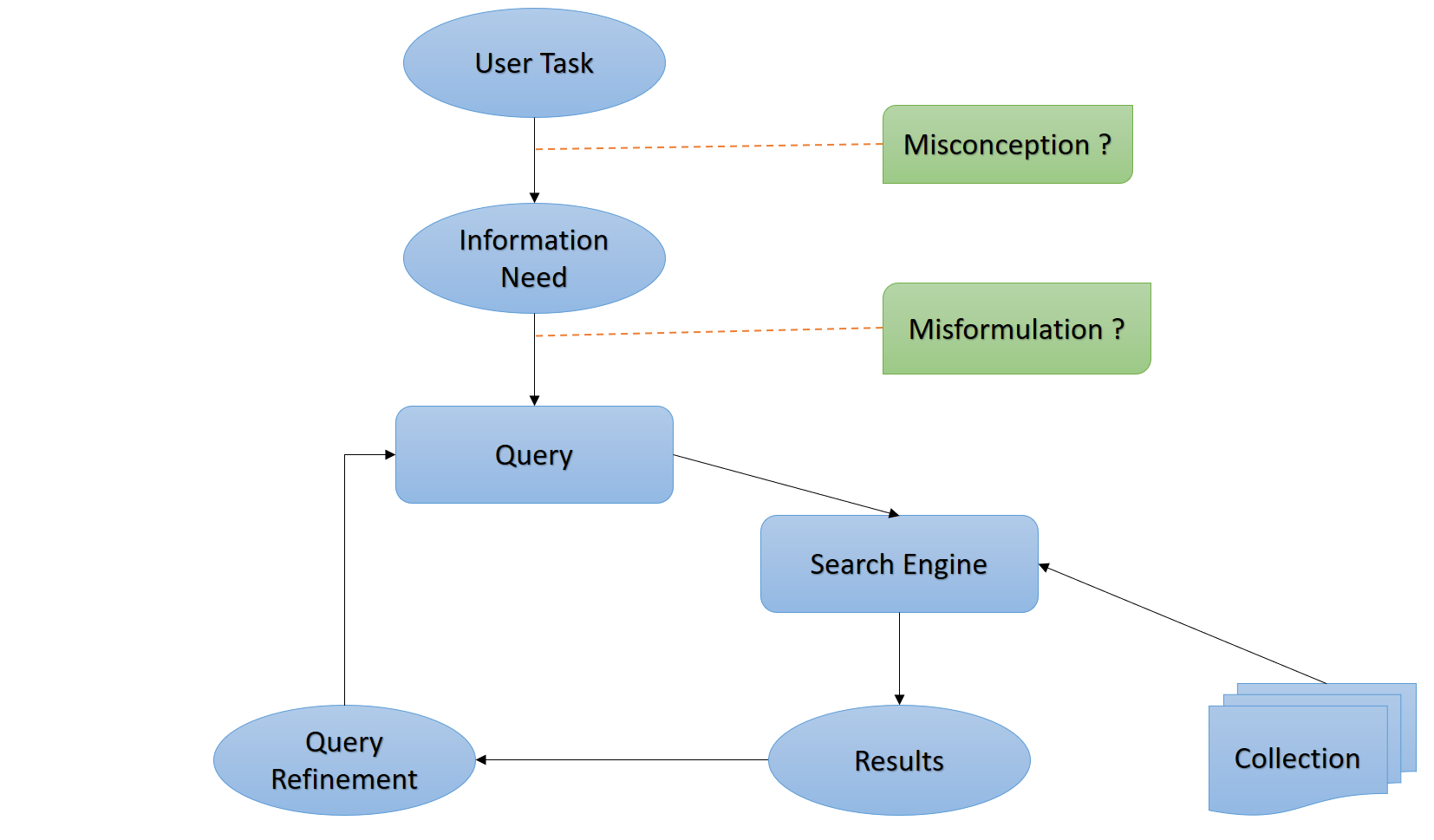
No matter how advanced the retrieval system is, it can\u2019t know if the information that we seek is the one that we actually need to complete our task, and neither if we are representing correctly our information need through the query.
Term-document indices matrices
The field of IR is closely related to algorithms and data structures, and the efficiency of a retrieval system depends heavily on how we represent the documents in our collection.
The most naive and natural way for such representation is the term-document indices matricesas shown in the figure below.
In this table, we can see immediately for each term of the collection, if it appears or not (0/1) in a given document (without counting the frequency with which it appears).
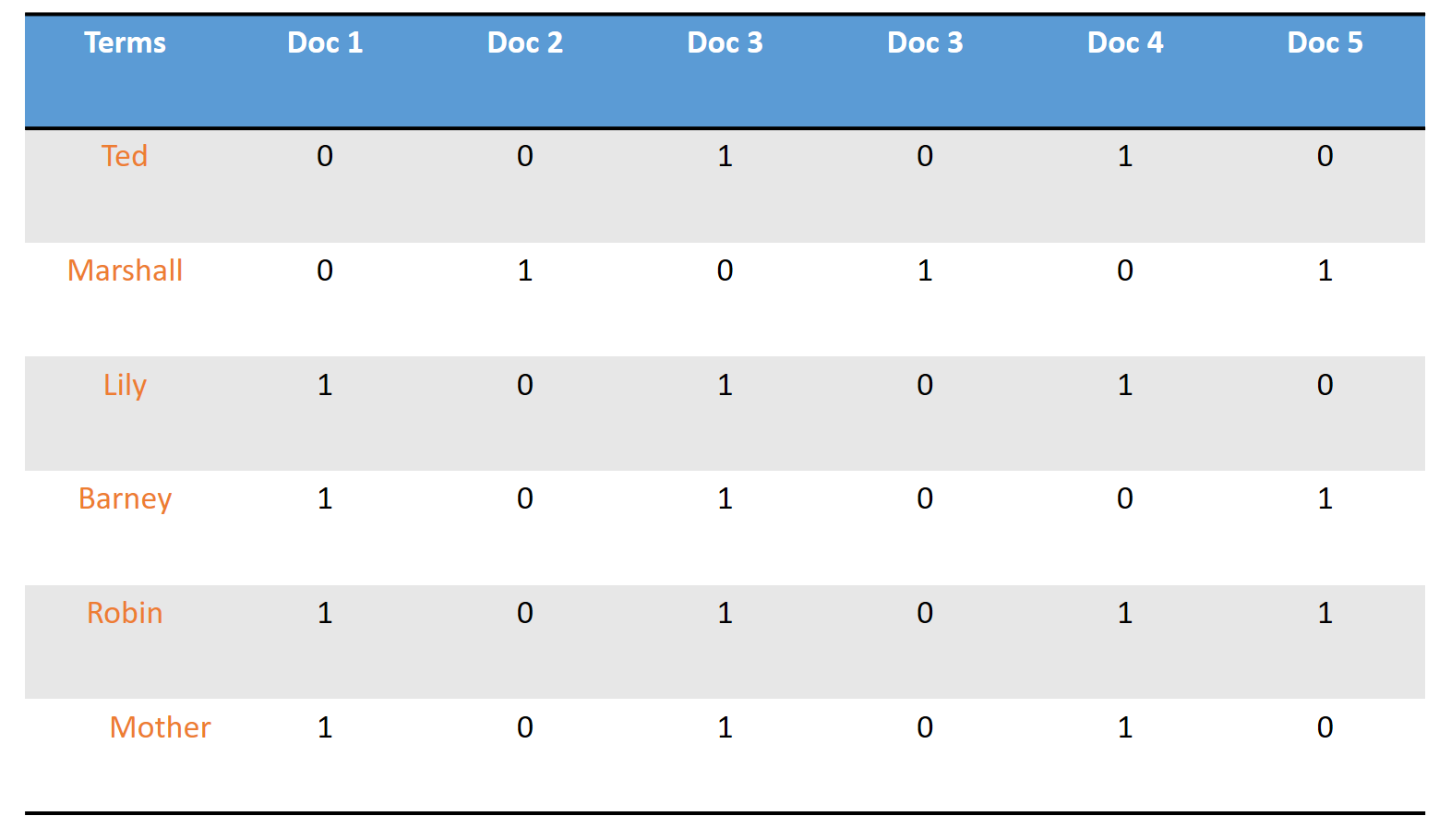
Using a representation of this type, it is easy to answer boolean queries. If, for example, I want all the documents where both the name Ted and Barney appear, I\u2019ll just take the rows I need and apply the & (and) operator to them:
001010 & 101001 = 001000 (just the third document)
This representation although very simple to implement is not good, it takes up a lot of memory space, we can do better.
Inverted Index
You can notice that the previous representation was really sparse, why don\u2019t we store only the non-zero entries?
For each term t in our collection, we store a list of only those documents that contain t, saving a lot of memory!

The figure above tells us that the word Ted is contained in documents 3,4,125,678,991 and 999.
With this structure, we can still handle boolean queries. To process the query "Ted and Lily" we just have to merge the two posting lists.
If the posting lists are both sorted by DocId we can merge them in linear time. Suppose the two lists have lengths of xand y, then the merge takes only O(x+y).
To handle the orboolean operation, one only needs to get all unique postings of both lists, while forthe notoperation you need all the documents that are notcontained in the posting list of that particular term.