LLM Evaluation & Benchmarks
Measuring performance, ELO ratings, benchmarks, and evaluation frameworks.
Guide & Approfondimenti

Google AI Studio: A Practical Guide to Prototyping with the Gemini API
Learn Google AI Studio by doing: prompt workflows, built-in tools, safety settings, pricing & rate limits, and a production checklist—plus when to use Vertex AI.

LMArena: How the Web’s Biggest LLM Leaderboard Works
LMArena explained: anonymous battles, Elo-style ratings, confidence intervals, category leaderboards, caveats, and a practical workflow to choose LLMs using human preference data.

Gemini 3 Pro vs GPT-5.2: AI Specialization in Dec 2025 LMArena
December 2025 LMArena updates show AI specializing: Gemini 3 Pro leads in creative tasks, while GPT-5.2 dominates WebDev. Discover the implications for AI users.

o3-mini vs. DeepSeek R1: Which AI Model Wins in Performance & Cost?
OpenAI’s o3-mini is here! Discover how this powerful AI model compares to DeepSeek R1, what it means for the future of AI, and why it’s a game-changer in reasoning and cost-efficiency. Read more now!
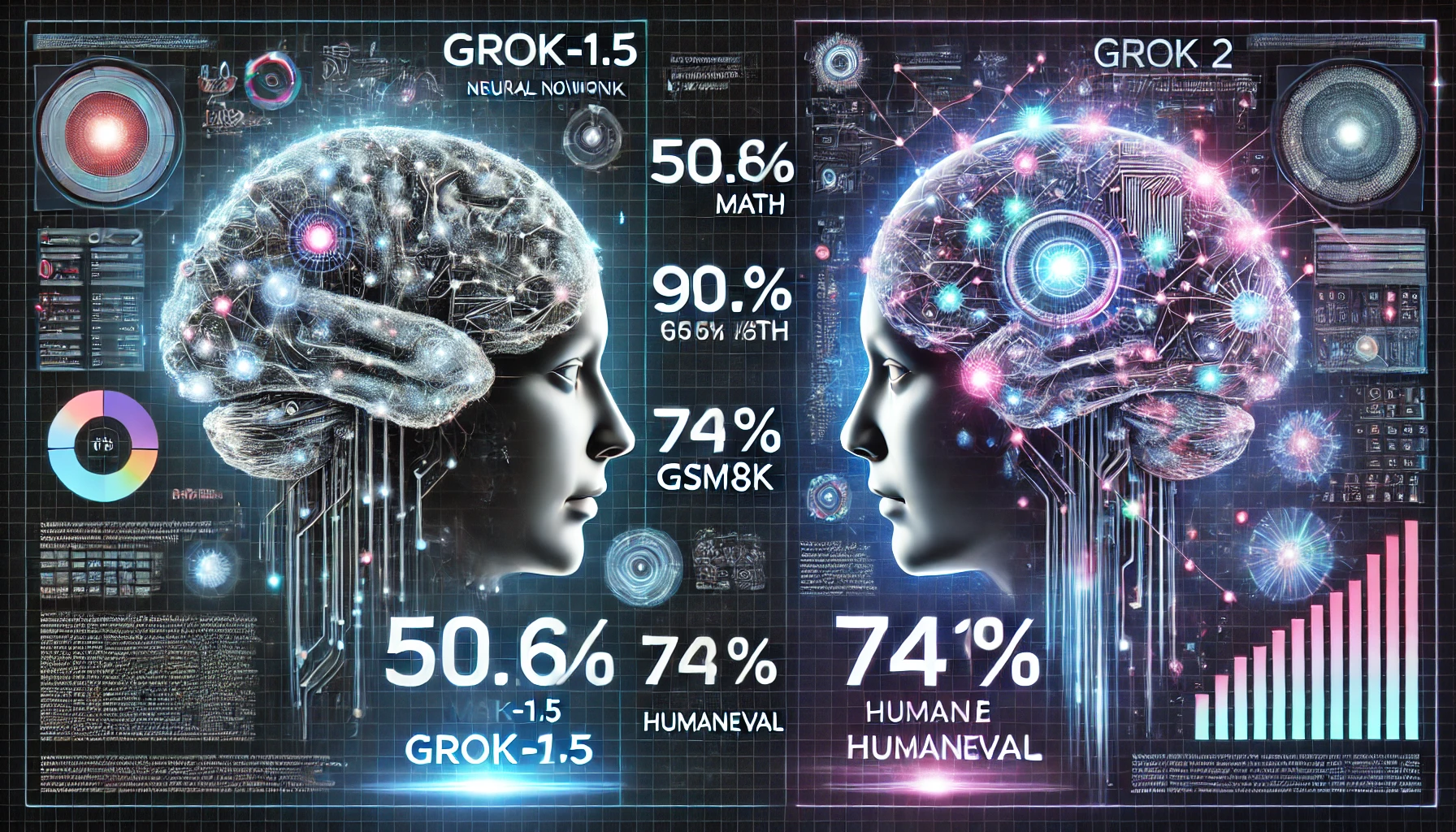
Grok Model: Redefining AI Capabilities and Performance Benchmarks
Discover xAI's Grok model and its evolution to Grok 2. Learn about groundbreaking AI advancements, benchmarks, and real-world applications reshaping industries.