

Enterprise RAG Blueprint: Router-First + Hybrid Search
FREESenior engineers, ML engineers, and tech leads designing production RAG systems and looking for a pragmatic, router-first blueprint.
A sophisticated, multi-stage pipeline for industrial-grade Retrieval Augmented Generation (RAG). It integrates advanced data ingestion, hybrid retrieval, rigorous reranking, router-first design, and built-in compliance for reliability, governance, and precision.
RAG 2026 Reference Architecture in a nutshell
Implement a semantic router and BM25+Vector hybrid search first. Do not add cross-encoders or tools pending measured RAGAS baseline failures.
The 2026 standard is a multi-stage pipeline: semantic router, hybrid search (RRF), cross-encoder reranking, and active guardrails.
Router-First design classifies intent (Fast, Standard, Deep), enabling zero-shot or cache hits that cut LLM inference costs entirely for simple queries 9.
Fused Retrieval Layer: combining dense (vector) and sparse (BM25 keyword) search via Reciprocal Rank Fusion (RRF) maximizes Day-1 relevance [4, 5].
Treat retrieved context as untrusted. Active guardrails block prompt injections, while semantic caching serves repeat workloads at near-zero latency [11, 13, 6, 7].
Cross-encoders increase precision but add ~200ms+ latency. The semantic router dynamically selects this path only for complex analytical queries 8.
This guide is a practical blueprint for enterprise RAG architecture (aka RAG pipeline / retrieval stack / context engineering): how to route queries, run hybrid search (BM25 + vectors), fuse results with RRF, add reranking, caching, guardrails, and measure quality with eval KPIs.
It’s written for senior engineers, ML engineers, and tech leads who already know RAG fundamentals and need a pragmatic router-first design for production.
Enterprise RAG architecture in 40 seconds (Router-First)
Route early, retrieve hybrid, fuse with RRF, rerank sparingly, guardrail always, evaluate continuously.
- Fast lane: cache/static answers (near-zero cost)
- Standard lane: hybrid retrieval (BM25 + vectors) + RRF
- Deep lane: tool/agent path when the query truly needs it
What Defines an Enterprise RAG Architecture in 2026?

The 2026 RAG reference architecture marks a fundamental transition from experimental prototypes to industrial-grade systems. The era of rudimentary Retrieval Augmented Generation, characterized by simplistic vector database uploads, has concluded. Instead, the modern standard is a sophisticated, multi-stage pipeline designed for reliability, governance, and precision.
As organizations define their enterprise AI roadmap, they are moving beyond simple semantic similarity. The 2026 architecture standardizes on an integrated workflow: advanced data ingestion, hybrid retrieval (combining keyword and vector search), and rigorous reranking. This architectural maturity is essential because RAG can improve answer reliability by grounding outputs in retrieved context — but you still need continuous evaluation to quantify faithfulness and context relevance in your domain [2, 3].
Crucially, this architecture treats trust as a structural component, not a policy afterthought. To master LLM practical fundamentals, one must understand that data flow requires protection. In regulated environments, anonymization/PII masking is often required for sensitive data, and should be treated as a first-class control in the pipeline [6, 7]. Without integrating these compliance features directly into the retrieval layer, organizations risk exposing PII and failing basic security requirements, which blocks high-value use cases in practice [6, 7].
The 2026 Shift:
- From: Single Vector Database → To: Hybrid Search + Reranking (+ optional Knowledge Graphs where the domain supports it)
- From: "Black Box" Retrieval → To: Auditable, Compliant Pipelines
- From: Static Indexing → To: Dynamic, Router-based Execution
Why Router-First Routing Is Essential in Modern RAG Architecture?

Early RAG implementations relied on a uniform, resource-intensive sequence for every user query: embedding, retrieval, reranking, and generation. By 2026, this linear approach is considered inefficient. The defining feature of modern enterprise architecture is a Router-First design, where a lightweight semantic classifier acts as the central traffic controller before any retrieval begins.
Treating every input as a complex research question significantly increases compute costs and diminishes user engagement. Unnecessary resource consumption occurs when simple queries, such as greetings or requests for static policy dates, are routed through computationally intensive processes like GPU-accelerated embedding and vector search. Instead, the 2026 reference architecture uses a semantic router to classify intent into three distinct lanes:
- Fast Lane (Cache/Static): Direct hits for common FAQs or greeting protocols. Zero retrieval cost, near-instant latency.
- Standard Lane (Vector + Keyword): The workhorse path for specific, factual queries. This triggers the hybrid search pipeline we discuss later.
- Deep Lane (Agentic/Tool-Using): Reserved for complex analytical tasks requiring multi-step reasoning (and optionally graph-based retrieval if your domain supports it).
This strategy extends beyond mere latency reduction; it is crucial for economic viability. By filtering distinct intents early, organizations avoid the "relevance ceiling" where simple queries get confused by complex retrieval logic, and complex queries fail because they weren't allocated enough compute [9].
The Efficiency Gap:
Implementing a semantic router can reduce LLM inference costs by diverting simple queries away from the heavy generation pipeline.
The actual savings depend on your traffic mix (how many queries qualify for Fast/Standard vs Deep), so measure it with routing KPIs (lane distribution, cost/query, p95 latency).
How Does the Fused Retrieval Layer Maximize Relevance with Hybrid Search and RRF?
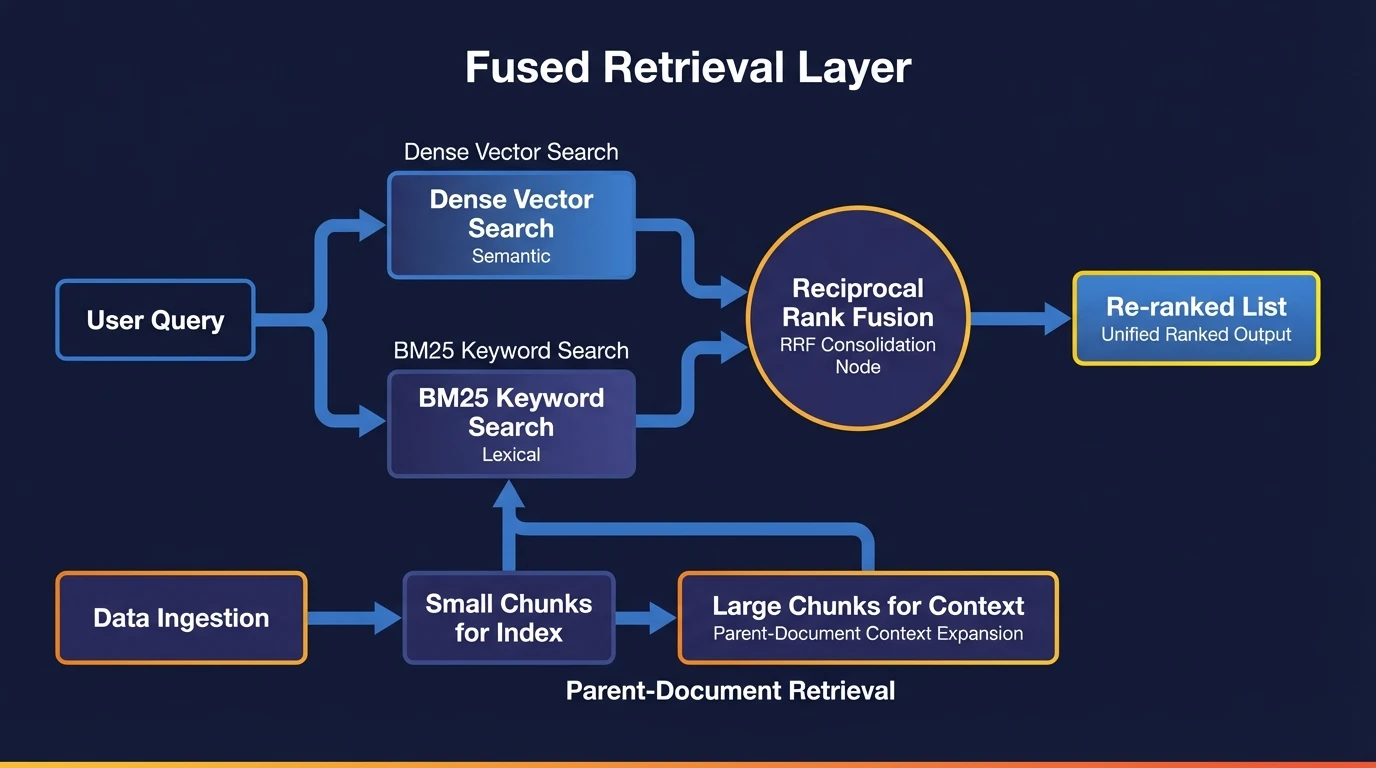
Reliance on simple vector search in early RAG implementations frequently resulted in a 'relevance ceiling,' limiting the specificity of retrieved information. While vector search excels at conceptual understanding, it often struggles with precise lexical distinctions, such as differentiating between "Policy A-12" and "Policy A-13." To solve this, the 2026 reference architecture standardizes on a Fused Retrieval Layer, moving beyond single-algorithm dependency.
The Mechanics of Hybrid Fusion
The core of this layer is hybrid search, which runs two parallel queries: a dense vector search for semantic meaning and a keyword (BM25) search for exact lexical matches. This combination is now standard practice, effectively capturing both the semantic intent and lexical specificity of a user's request [5, 4].
To reconcile these disparate results, Elastic and other major search providers recommend Reciprocal Rank Fusion (RRF) [4, 5]. Unlike normalization of arbitrary score thresholds, which can be mathematically problematic, RRF ranks documents based on their ordinal position within each retrieval list. The logic prioritizes consensus: if a document appears in the top 5 for both keyword and vector search, it ascends to the top of the final context window.
RRF logic effectively boosts consensus candidates
fused_docs = rrf_fuse(ranked_lists, top_n=6)
This snippet demonstrates the consolidation logic commonly implemented in production architectures [5]. However, better ranking cannot fix broken data. Therefore, fusion is typically paired with parent-document retrieval [10]. By indexing small chunks for search precision but returning larger parent spans to the LLM, the system ensures the model receives complete paragraphs rather than fragmented sentences.
How Do Caching and Guardrails Enhance RAG System Reliability and Efficiency?
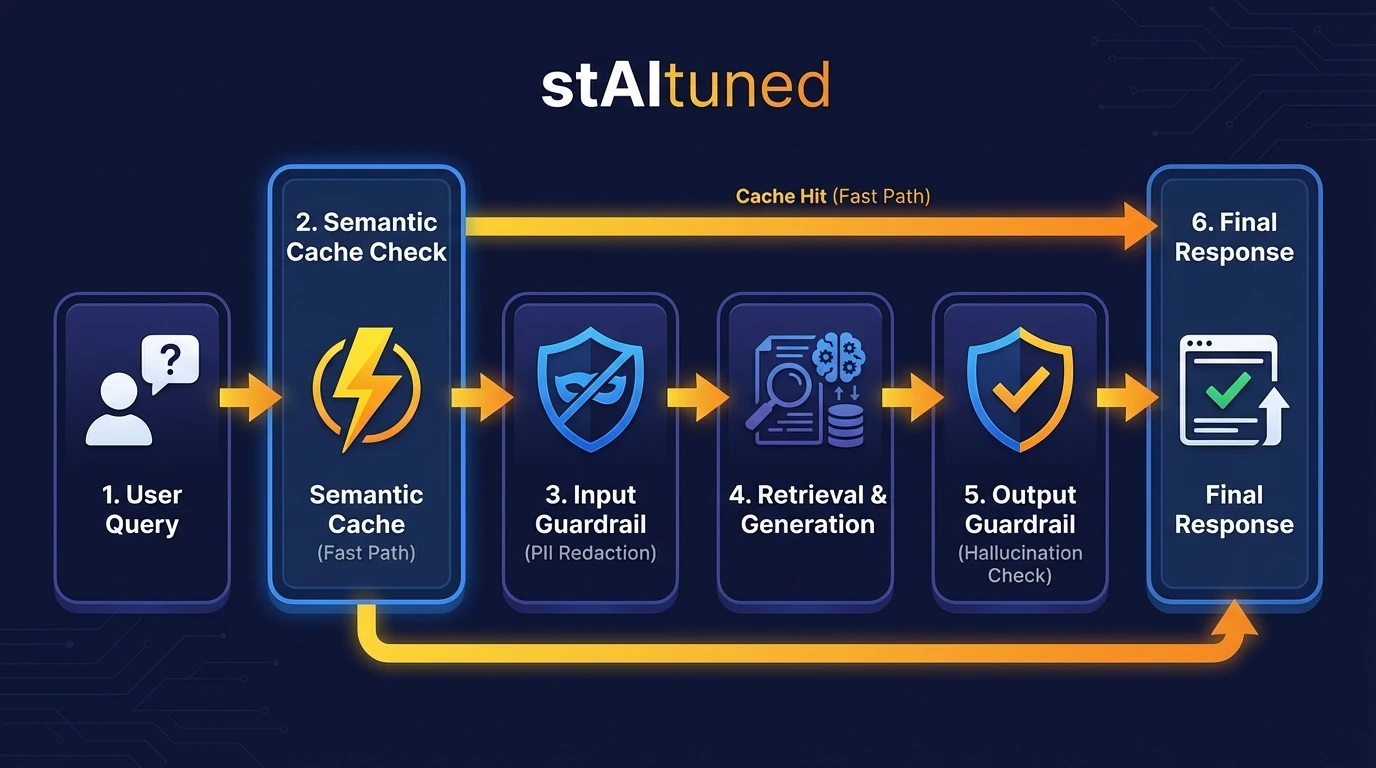
In the 2026 RAG architecture, reliability and efficiency are not merely operational optimizations but fundamental structural components. Building a scalable RAG system necessitates the integration of dedicated caching and compliance layers.
The Efficiency Layer: Smart Caching
The most efficient query is one that bypasses the LLM entirely, often addressed by a cache. Caching serves as a primary defense mechanism against escalating API costs and latency. Instead of re-computing embeddings for every recurring question - like "What is the Q3 revenue?" - a semantic cache returns the validated result instantly.
Implementing an effective semantic cache (and/or intermediate-state caching) can significantly optimize performance for high-repeat workloads [11, 12, 13]. The realized benefit scales with cache hit-rate and invalidation strategy.
The Trust Layer: Compliance Guardrails
While caching optimizes resource expenditure, guardrails safeguard business operations. Enterprise RAG requires a "security-by-design" approach where compliance is an active filter, not a policy document. In regulated environments, anonymization/PII masking is often required for sensitive data, and should be treated as a first-class control in the pipeline [6, 7].
Untrusted Retrieval and Security
A critical addition to modern guardrails is the treatment of retrieved documents as untrusted input. Malicious actors can use prompt injection (indirect or direct) or data exfiltration techniques through manipulated retrieval context. Without integrating these compliance features, organizations risk exposing PII and failing basic security requirements, which blocks high-value use cases in practice [6, 7]. To mitigate these risks, follow the OWASP Top 10 for LLM Applications and treat the retrieval-generation boundary as a security perimeter.
Critical Insight: Caching and guardrails must be treated as integrated, active components. Caching provides the necessary latency budget to accommodate the computational overhead of robust security filters.
What are the Practical Trade-offs for Optimizing RAG Cost, Latency, and Quality?

The Iron Triangle: Cost, Latency, and Quality
In practice, you are continuously trading off cost, latency, and answer quality across retrieval depth, reranking, and context length. Design for measurement-first so you can tune these trade-offs with real production KPIs [1].
The Price of Precision
A prevalent point of friction arises within the re-ranking layer. Adding a cross-encoder step significantly boosts quality by strictly re-ordering documents based on deep semantic relevance. However, this precision comes with a tax. Cross-encoders are computationally intensive - often slower than bi-encoders - and are typically used to rerank the top-k results rather than the entire corpus [8].
Teams can often mitigate this trade-off by employing Multi-query generation. By having the LLM generate query variations (e.g., "Explain with examples"), retrieval recall and relevance can improve without the heavy latency penalty of re-ranking every single result.
A crucial strategic perspective reveals that RAG can offer superior scalability and cost-efficiency compared to frequent LLM fine-tuning. For enterprise applications prioritizing data freshness, RAG's operational expenditure is often significantly lower than recurrent model retraining cycles, though the choice depends on specific latency and consistency requirements.
To help navigate these choices, here is how the key components stack up:
| Component | Latency Impact | Cost Impact | Quality Gain |
|---|---|---|---|
| Vector Search | Low (~50ms) | Low | Baseline |
| Hybrid Search | Medium | Low | High (Keyword precision) |
| Cross-Encoder | High (200ms+) | High (GPU inference) | Very High (Deep relevance) |
| Agentic Router | Variable | Medium | Max (Context-aware pathing) |
The 2026 reference architecture isn't about picking the "best" component; it's about using a router to dynamically select the cheapest path that satisfies the query's quality requirement.
What Are Key Considerations for Building and Evolving Enterprise RAG Architectures?
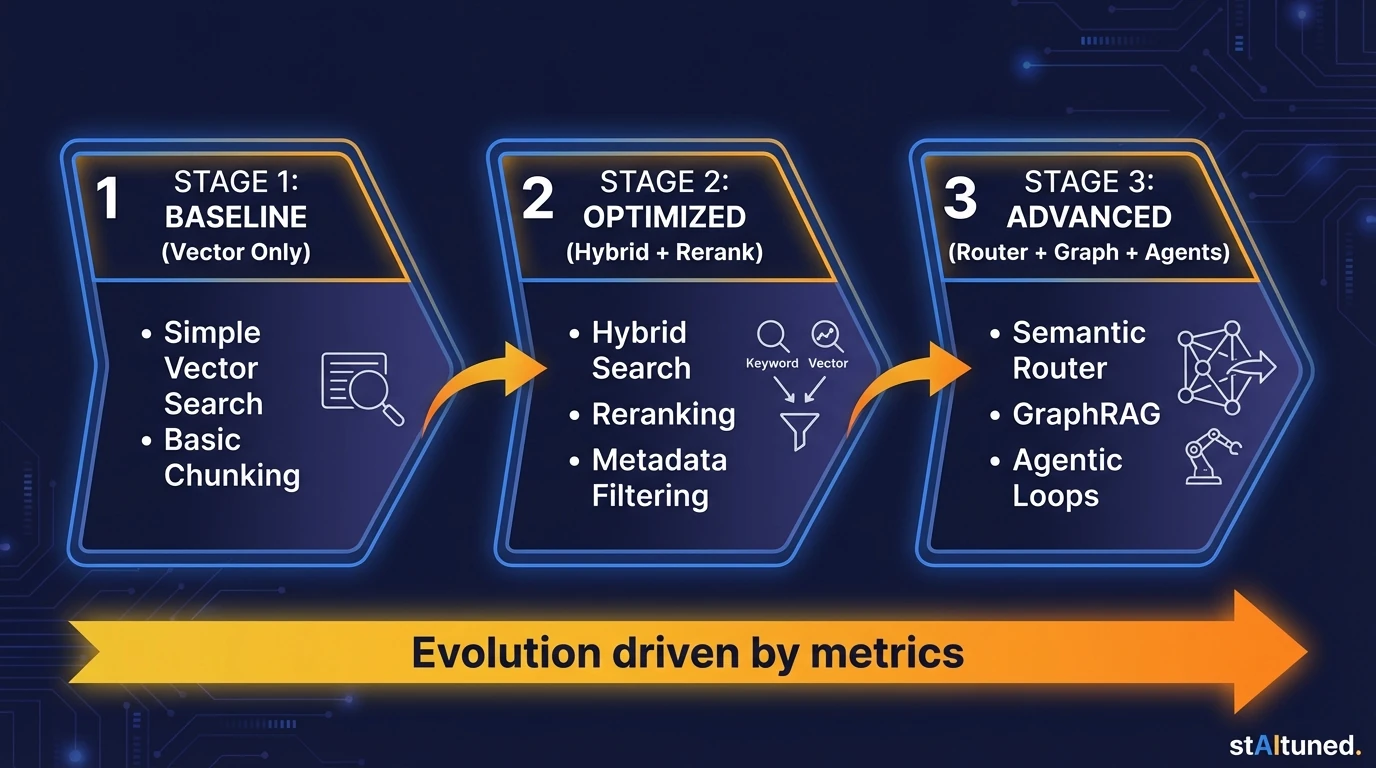
Developing a production-ready RAG system constitutes an ongoing product lifecycle, rather than a singular project. A common error is the premature deployment of the complete '2026 architecture,' including components like semantic routing, graph fusion, and multi-agent loops, during initial implementation. Instead, success comes from a phased, metric-driven evolution.
Start with a verifiable baseline. Launch a simplified pipeline (ingest, chunk, embed, retrieve) to establish performance benchmarks. Only introduce complexity like Reciprocal Rank Fusion (RRF) or semantic splitting when your metrics demand it.
Measurement is Part of the Architecture
In 2026, you cannot optimize what you do not measure. Evaluation should be integrated into the architecture itself, not treated as a post-hoc analysis. Utilize frameworks like RAGAS (Retrieval Augmented Generation Assessment) to automate the measurement of faithfulness, answer relevance, and context precision [3]. AWS recommends a continuous evaluation workflow to ensure the system remains reliable as data and user needs evolve [2].
Treat security as architecture. In enterprise environments, data governance cannot be an afterthought. Security-by-design means features like PII anonymization and untrusted retrieval mitigation (guardrails) are mandatory components of the ingestion and retrieval layers [1, 6].
Finally, robust observability must be instrumented from inception. Tracking granular metrics - like the specific latency cost of the reranking step - is the only way to decide if the quality gain is worth the speed penalty [2]. Use Architecture Decision Records (ADRs) to document these trade-offs as your system matures.
Critical Guidance: Avoid premature over-engineering. Establish a foundational baseline, enforce data layer security, and introduce advanced "2026" complexities only when validated by evaluation metrics and real production KPIs.
FAQ
Tip: Each question below expands to a concise, production-oriented answer.
What are the key distinctions of the RAG 2026 reference architecture compared to earlier RAG systems?
The 2026 RAG architecture moves beyond simple vector search to a sophisticated, multi-stage pipeline. It integrates hybrid retrieval (keyword and vector search), rigorous reranking, and treats trust as a structural component with mandatory anonymization. This industrial-grade approach ensures reliability, governance, and precision for enterprise AI.
Why is a Router-First design crucial for efficiency and cost reduction in 2026 RAG systems?
A Router-First design uses a lightweight semantic classifier to intelligently direct user queries into 'Fast,' 'Standard,' or 'Deep' lanes. This avoids unnecessary compute for simple queries, reducing costs and latency. The actual savings depend on the traffic mix and are measured with routing KPIs like lane distribution and cost per query.
How do Hybrid Search and Reciprocal Rank Fusion (RRF) improve retrieval relevance in RAG 2026?
The Fused Retrieval Layer combines hybrid search, which runs parallel dense vector and keyword (BM25) queries, to capture both semantic meaning and lexical specificity. Reciprocal Rank Fusion (RRF) then consolidates these disparate results by prioritizing documents that appear high in both ranked lists, effectively boosting consensus candidates and overcoming the 'relevance ceiling' of single-algorithm approaches.
What roles do caching and guardrails play in enhancing RAG system reliability and efficiency?
Caching acts as an efficiency layer, storing validated results for recurring queries to reduce latency and cut API costs. Guardrails form a trust layer, implementing "security-by-design" through PII masking and treating retrieved context as untrusted input. This approach ensures compliance and prevents risks like prompt injection or hallucinations.
What are the main trade-offs to consider when optimizing RAG for cost, latency, and quality?
Optimizing RAG involves balancing the "Iron Triangle" of Cost, Latency, and Quality. For instance, using a cross-encoder for higher quality introduces significant latency and cost. Strategies like multi-query generation can improve quality without the heavy reranking penalty. Enterprises should prioritize RAG over frequent LLM fine-tuning for better scalability and cost-efficiency when data freshness is key. Starting with a simpler baseline and adding complexity based on metrics is advised.
References
- AWS Prescriptive Guidance — Retrieval Augmented Generation options and architectures
- AWS ML Blog — Evaluate the reliability of RAG applications using Amazon Bedrock
- RAGAS — Automated Evaluation of Retrieval Augmented Generation (paper)
- Elastic Docs — Hybrid search (recommends RRF for hybrid)
- Elastic Docs — Reciprocal Rank Fusion (RRF) API + formula
- OWASP — Top 10 for Large Language Model Applications (Prompt Injection, etc.)
- OWASP Cheat Sheet — LLM Prompt Injection Prevention
- Sentence-Transformers Docs — Cross-Encoders (rerankers)
- Routing Survey (LLM systems) — Implementing Routing Strategies in LLM-Based Systems
- LangChain (JS) — ParentDocumentRetriever
- RAGCache (paper) — Efficient Knowledge Caching for RAG
- Prompt Cache (paper) — Attention reuse for low-latency inference
- AWS Database Blog — Semantic cache with ElastiCache + Bedrock
Goal is to minimize latency and costs for simple or common queries
Route queries to the **Fast Lane** (Cache/Static) for zero retrieval cost and near-instant response.
Query requires specific, factual information
Use the **Standard Lane** (Vector + Keyword) which triggers the hybrid search pipeline.
Query requires complex analytical tasks, multi-step reasoning, or tool-use
Route to the **Deep Lane** (Agentic/Tool-Using) for advanced processing [1].
Need to maximize relevance by combining disparate search results (e.g., keyword and vector)
Employ **Reciprocal Rank Fusion (RRF)** to consolidate results based on ordinal position [4, 5].
Dealing with sensitive enterprise data (e.g., PII, or untrusted inputs)
Implement **guardrails** (PII masking and prompt injection prevention) before generation [6, 7].
Seeking superior scalability and cost-efficiency for data freshness
Prioritize **RAG** over frequent LLM fine-tuning.
Premature Over-engineering
Start with a verifiable baseline, and only introduce complexity like RRF or hybrid search when justified by metrics.
Relying on Simple Vector Search
Standardize on **hybrid search**, combining dense vector search for semantic meaning with keyword (BM25) search for exact matches [4, 5].
Treating Compliance and Security as an Afterthought
Adopt a 'security-by-design' approach; treat retrieved documents as untrusted input to mitigate exfiltration risks [6, 7].
Uniform, Resource-Intensive Query Processing
Implement a **Router-First design** with a semantic classifier to direct queries to appropriate lanes (Fast, Standard, Deep) based on intent, reducing unnecessary compute costs.
Updates: Updated on Feb 23, 2026 • v1.1ShowHide
- Rewrote the intro for GEO clarity (enterprise RAG / retrieval stack / context engineering synonyms).
- Added a 40-second router-first summary section (Fast/Standard/Deep lanes).
- Adjusted headings to better match 'enterprise RAG architecture' terminology.
Older updates
- Published the first version of the router-first enterprise RAG reference architecture guide.




