

Large Concept Models: Meta’s Next Frontier in AI
FREEAI researchers, senior developers, and system architects exploring the next generation of efficient, multilingual, and long-form generative architectures.
A non-token-based language model that predicts sequences of semantic embeddings (concepts) in a shared representation space like SONAR.
What is a Large Concept Model (LCM)?
LCMs move AI from token-level guessing to sentence-level reasoning, prioritizing meaning over characters.
LCMs model language at the 'concept' level using SONAR sentence embeddings instead of character tokens.
They operate on sequences an order of magnitude shorter than traditional LLMs, improving efficiency and coherence.
SONAR enables multilingual decoding: the same predicted concept stream can be decoded into many text languages (text I/O: 200), without re-running the reasoning step (speech output is English in the paper setup).
Best used as a 'Semantic Planner' in hybrid systems where high-level coherence is prioritized over string exactness.
Answer in 30 seconds
- LCM = LM in sentence-embedding space: Predicts semantic representations (concepts) rather than character-level tokens.
- Pros: Enhanced coherence for long-form content, cross-lingual semantic stability, and drastic sequence length reduction.
- Cons: Struggles with string exactness (code, JSON) and current decoder bottlenecks.
- Best fit: Long-form summarization, speech↔text semantic pipelines, and global-scale semantic planning.
Introduction
The release of Large Concept Models (LCMs) by Meta marks a promising shift in the evolution of generative AI [2]. Diverging from traditional token-based Large Language Models (LLMs), LCMs operate on a higher level of abstraction, processing semantic representations known as "concepts." This approach enables language-agnostic reasoning and structural coherence that often eludes token-level predictors. This article explores the mechanics of LCMs, their foundation in the SONAR space, and their potential role in modern AI architectures.
Understanding the Core of Large Concept Models
The Shift from Tokens to Concepts
Traditional LLMs, such as GPT or BERT, function by predicting and generating output at the token level—words or subwords—using autoregressive or masked training techniques. While effective, this approach often struggles with maintaining contextual coherence over extended outputs and lacks abstraction beyond the token level.
In this work, a "concept" is explicitly a sentence embedding in the SONAR representation space. The model learns to predict the next sentence representation, then a decoder maps those representations back to text (or speech-related outputs depending on the setup). Sentences were chosen as the fundamental unit to improve language-independence and semantic density compared to sparse word-level tokens. This high-level abstraction allows the model to:
- Capture Meaning Holistically: By working at the sentence level, LCMs ensure that outputs are contextually coherent and semantically rich, avoiding the "local context" trap of token-based predictors.
- Enable Multimodal Integration: SONAR embeddings are language-agnostic; in this work, text and speech are the focus, with vision being an open extension for future research.
What’s actually new here?
- Unit = sentence embedding: The model predicts dense semantic vectors instead of character-level tokens.
- Frozen decoder/encoder: Reasoning happens entirely in the fixed SONAR space, decoupling semantic planning from linguistic layout.
- Zero-shot translation by design: You can decode the same predicted concept stream into any supported language without re-reasoning or separate translation steps.
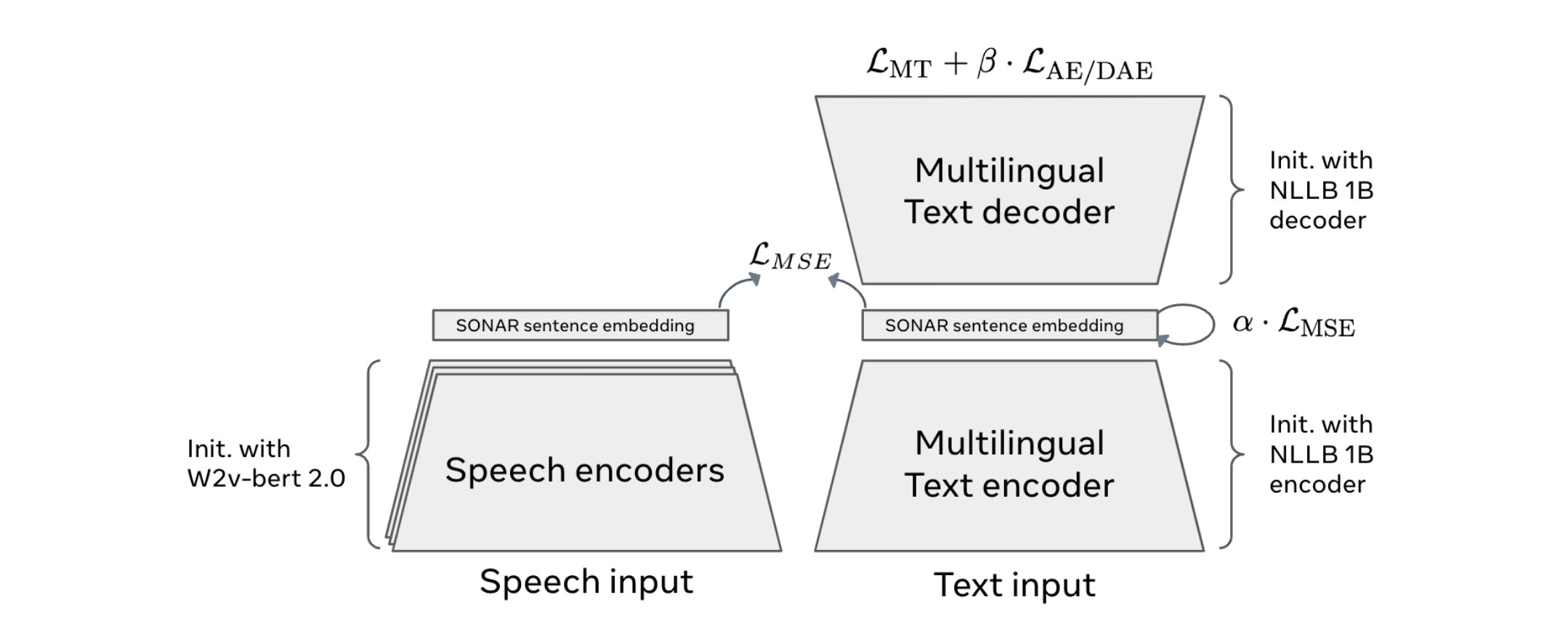
The SONAR Embedding Space
A pivotal innovation behind LCMs is the use of the SONAR embedding space. According to the original research, SONAR provides a shared embedding space that supports:
- Text input/output: 200 languages.
- Speech input: 76 languages.
- Speech output: English.
Note: Official SONAR coverage (200 text, 76 speech input) may differ across releases; check the official repository [4] for current listing.
LCMs build on this to model sequences in sentence-representation space for [1]:
- Autoregressive Sentence Prediction: Instead of predicting the next token, LCMs predict the next sentence embedding in the SONAR space.
- Conceptual Diffusion Models: Advanced variants of LCMs use diffusion-based generation to interpolate and generate embeddings in the SONAR space [2].
- Quantized Space Operations: Some LCMs operate within quantized SONAR spaces, enabling efficient and precise semantic representation generation.
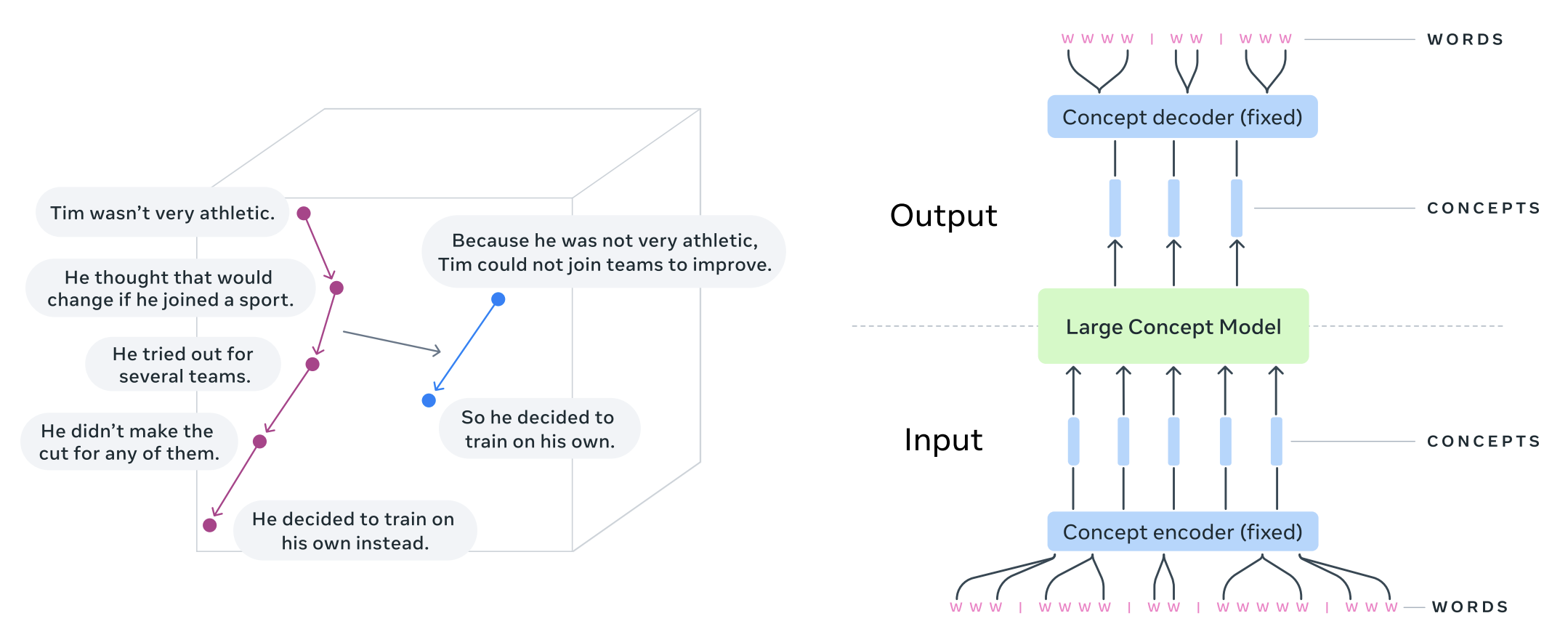
How Large Concept Models Work
LCMs streamline the generation process by offloading character-level heavy lifting to dedicated encoders and decoders. The standard pipeline is:
- Segment & Encode: Input text or speech is segmented (usually at sentence boundaries) and mapped into fixed-size SONAR vectors.
- LCM Processing: The model predicts the next concept (vector) in the sequence. This can be done via Autoregressive Regression or Diffusion.
- Decode: A modality-specific decoder (e.g., a text-decoder) maps the predicted vector back into human-readable format.
While currently linear, researchers are exploring hierarchical conditioning where higher-level "summary" representations could guide lower-level "detail" representations, further improving long-range coherence.
Key Features and Advantages
Language and Modality Agnosticism
LCMs are inherently versatile. By operating on concepts rather than tokens, they can:
- Process multilingual data without requiring separate models for each language.
- Integrate text and speech modalities today, with a foundation built for future extensions.
Enhanced Coherence and Context
Traditional token-based models often falter in generating long-form content due to local context limitations. LCMs, working at a higher abstraction level, maintain coherence across extended outputs, making them ideal for complex tasks like summarization.
| Feature | Token-based LLM | Large Concept Model (LCM) |
|---|---|---|
| Generation Unit | Tokens (words/sub-words) | SONAR Sentence Embeddings |
| Sequence Length | Long (1000s of tokens) | Short (10s of concepts) |
| Core Strength | Precise string editing, Code | Semantic stability, Planning |
| Failure Mode | Hallucinated facts, repetition | Hallucinated concepts, string errors |
Multilingual and Multimodal Capabilities
Leveraging the SONAR embedding space, LCMs build on a foundation that supports 200 languages for text and dozens for speech. This enables cross-modality tasks, such as generating textual descriptions of speech or vice versa, while maintaining semantic consistency across linguistic boundaries.
Performance & Use Cases (what the paper actually shows)
LCMs are evaluated on generative tasks where high-level semantic stability matters (summarization, summary expansion, multilingual summarization). The main automatic metric reported across these sections is ROUGE-L (F-measure). [2]
How to read ROUGE-L for LCMs (don’t overfit the metric) [2]
- ROUGE-L rewards lexical overlap, so it often favors token-LLMs that “match the reference wording,” not necessarily the best global structure.
- LCMs can be semantically right but lexically different (paraphrases / concept-level rewrites), so ROUGE may underestimate them.
- In summary expansion, lower ROUGE can still mean “good” if the model adds plausible new sentences while staying on-topic (ROUGE penalizes novelty).
- Use ROUGE as a baseline signal, then break ties with human eval on: coherence, faithfulness, and constraint satisfaction.
- For production, test string-exactness tasks (code/JSON/schema): these are known weak spots of concept-space generation.
1) Summarization (CNN/DailyMail, XSum) — ROUGE-L snapshot
| Model (paper labels) | Paradigm | CNN/DM ROUGE-L | XSum ROUGE-L |
|---|---|---|---|
| Llama-3.1-8B-IT | LLM | 34.97 | 20.35 |
| Two-Tower-7B-IT (LCM) | LCM | 36.47 | 23.71 |
| T5-3B (baseline) | Seq2Seq | 37.56 | 17.11 |
Takeaway: in these settings, the LCM is not “slightly behind”: it’s ahead of Llama-3.1-8B-IT on both CNN/DM and XSum under ROUGE-L, while remaining competitive with strong task-specific baselines.
2) Summary Expansion — ROUGE-L is mixed (not a single “trend”)
| Model (paper labels) | Paradigm | CNN/DM ROUGE-L | XSum ROUGE-L |
|---|---|---|---|
| Llama-3.1-8B-IT | LLM | 42.52 | 26.26 |
| Two-Tower-7B-IT (LCM) | LCM | 37.76 | 28.84 |
| T5-3B (baseline) | Seq2Seq | 37.56 | 31.39 |
Interpretation: expansion rewards different behaviors depending on dataset.
- On CNN/DM, Llama leads on ROUGE-L.
- On XSum, the LCM beats Llama on ROUGE-L (but not T5).
So: “LLMs always win at expansion” would be an overstatement.
3) Multilingual summarization (XLSum) — where LCM really stands out
The strongest “surprise” result is zero-shot multilingual generalization: the LCM (Two-Tower-7B-IT) substantially outperforms Llama-3.1-8B-IT on English in XLSum (23.5 vs 20.7 ROUGE-L) and slightly on the average over the shared supported languages (20.2 vs 19.7). The paper also reports strong ROUGE-L on several low-resource languages and 30.4 on Vietnamese. [2]
Why this matters: the LCM was trained only on English and still generalizes well across languages thanks to the SONAR concept space. [2]
Use Cases
- Long-form Summarization with Structure Constraints: When you need a 10-page document summarized into a coherent narrative with specific structural flow that token-models often lose.
- Cross-lingual Semantic Transfer: Training on one language and generating in another while maintaining "semantic stability" rather than literal word-for-word translation.
- Speech↔Text Semantic Pipelines: Leveraging SONAR's native speech support to build pipelines that understand the meaning of speech directly and pivot to text generation without intermediate transcription.
Production architecture (LCM planner + token-LLM realizer)
A powerful way to view an LCM is as a Semantic Planner in a hybrid pipeline:
- LCM (The Planner): Maps out the high-level semantic trajectory, ensuring global coherence and logical transitions across long-form content.
- LLM (The Realizer): A high-precision model (like Llama 3 or GPT-4o) handles the "surface realization"—turning predicted concept embeddings into perfectly formatted prose, JSON, or code.
This approach combines the structural stability of LCMs with the character-level precision of token-LMs. [2]
Challenges and Future Directions
Efficiency: "Order of Magnitude" Gains
The key efficiency lever for LCMs is the drastic reduction in sequence length. Because LCMs operate at the sentence level, they work with sequences that are at least an order of magnitude shorter (e.g., 50 sentences vs. 1,000 tokens) [2]. The paper explicitly assumes an average sentence length of 10–20 tokens, which is why concept sequences are “at least an order of magnitude shorter” than token sequences for long-form contexts. Since Transformer complexity grows quadratically with sequence length, this reduction fundamentally changes the cost profile. While predicting a high-dimensional embedding is heavier than a single token, doing it 20x fewer times allows for massive context windows that would be computationally prohibitive for token-LMs.
Interpretability
The abstraction level of concepts makes it challenging to trace how specific outputs are derived. Improving interpretability will be crucial for trust and transparency.
Expanding Modalities
While LCMs currently excel in text and speech, extending their capabilities to include vision and other data types remains an active area of exploration.
Two families of LCMs: autoregressive regression vs diffusion in concept space
For developers and researchers, it's important to note that LCMs aren't a single architecture but a family of approaches:
- Autoregressive Regression: Predicts the next embedding vector directly using a regression loss (typically MSE).
- Diffusion Variants: Uses a diffusion process to generate the next embedding, offering more flexibility in interpolating between "concepts" and potentially better diversity in generation.
The choice depends on whether you value deterministic semantic flow or the ability to explore conceptual variations.
Failure Modes & Mitigations: Where LCMs Break
Despite their promise, LCMs face specific "expert" challenges:
- Not a factuality upgrade: The LCM is a semantic planner, not a grounded truth machine. It can still hallucinate complex concepts if the training data or input is flawed.
- String Exactness: Tasks requiring exact character matching (code, JSON, specific naming) are high-risk. Mitigation: Use LCMs for the "draft/plan" and an LLM for final "surface realization" or serialization.
- Error Propagation: A semantic error in one sentence embedding can cause the model to "hallucinate" an entire concept. Mitigation: Implement validation steps at the concept-space level before decoding.
- Decoding Artifacts: The decoder can reintroduce token-level artifacts. Mitigation: Post-process LCM outputs with lightweight grammar or schema-checkers.
Conclusion
Large Concept Models represent a paradigm shift in AI, moving from token-level processing to conceptual reasoning. By leveraging semantic embedding spaces like SONAR, LCMs offer significant gains in coherence, versatility, and multilingual support [3]. As Meta continues to refine this technology, the potential applications—from structured planning to multimodal pipelines—are vast. LCMs pave the way for a future where AI models meaning directly, bridging the gap between tokens and true semantic understanding.
References
Large Concept Models GitHub Repository
Large Concept Models: Language Modeling in a Sentence Representation Space (Meta AI Research)
SONAR: Sentence-Level Multimodal and Language-Agnostic Representations
You need long-form structural coherence or zero-shot multilingual generation
Experiment with LCMs as a semantic planner.
You need character-level precision (code, JSON, exact formatting)
Stick to token-based LLMs like Llama 3 or GPT-4o.
You need to process speech and text in a shared semantic space
Use SONAR-based LCMs for a unified pipeline.




