

LLM costs aren’t a pricing problem: it’s architecture
FREEAI engineers and product teams operating production RAG/agentic systems who need to reduce total cost of ownership, improve reliability, and keep debugging complexity under control.
The cumulative cost of unpredictability in LLM systems, including retries, branching failures, observability overhead, and engineering time spent diagnosing stochastic behavior.
Architecture-First LLM Cost Control
Treat the LLM as an expensive escalation path, not a default. Shift complexity from runtime debugging to upfront architectural routing.
Token pricing is a micro-optimization. The dominant cost driver is Operational Entropy: the engineering debt of debugging stochastic, multi-step agentic chains.
Router-First Architecture is the primary control mechanism. Triage 80% of traffic to specialized SLMs (Local/Fast) and use large reasoning models only as an intentional escalation path.
Reliability decays multiplicatively. A 10-step chain with 97% individual step reliability yields only ~74% total success rate. Minimize depth to reduce the 'Unreliability Tax'.
Track Escalation Rate (<20% target) and Bimodal Latency to make system economics observable. If debugging time dominates API spend, fix your component boundaries, not your prompts.
Most teams try to reduce LLM costs by switching models or limiting tokens. In production, this is a micro-optimization. The dominant cost driver is architecture.
This article explains why "fully agentic" architectures often fail economically over time, not because tokens are expensive, but because entropy is expensive. We will explore how hybrid systems with specialized Small Language Models (SLMs) reshape the cost curve by trading theoretical flexibility for operational control.
What “cost” really means in LLM systems
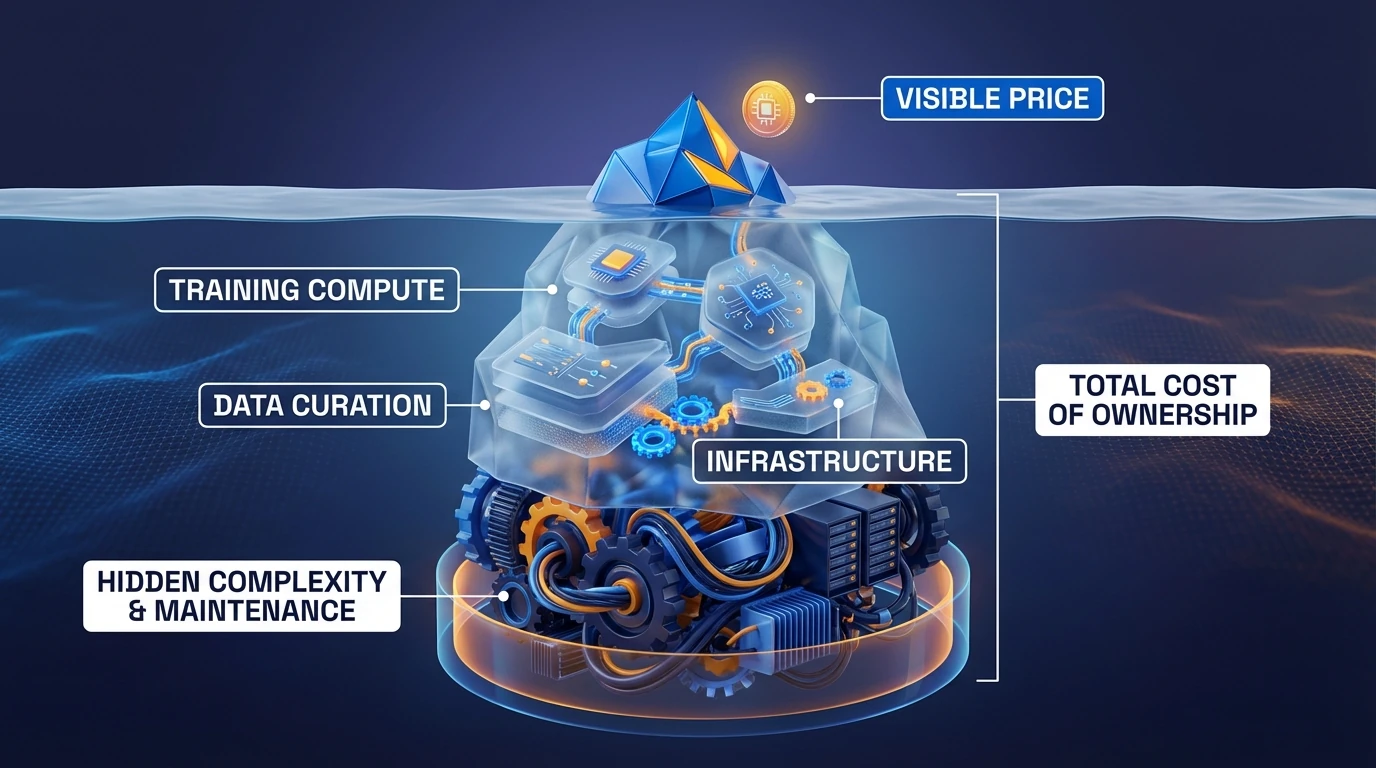
Token pricing is the most visible cost and often the least relevant variable in the TCO equation (Total Cost of Ownership = Tokens + Engineering & Operational Overhead). In a production environment, the TCO is dominated by the Cost of Control:
- Engineering time spent debugging nondeterministic failures.
- Latency overhead from retries and verification loops.
- Cascading failures in multi-step pipelines requiring manual intervention.
- Observability tax: the sheer volume of logs needed to trace a single request.
The Reality: A $0.01 API call that triggers a 2-hour debugging session for a senior engineer effectively costs $300. The dominant cost is not inference; it is the cost of unpredictability.
The core mismatch: Reasoning vs. controllability

Agentic architectures, often built on top of RAG pipelines, promise autonomy. In practice, the operational issues show up exactly where the architecture adds depth, retries, and branching (see also an interesting article about Router-First design notes). In demos, they feel magical. In production, a structural mismatch emerges: reasoning capability scales faster than operational controllability.
Each additional "reasoning step" in an agent chain introduces:
- More probabilistic branching points.
- More intermediate states to track.
- New, often silent, failure modes.
The result is a system that becomes more powerful and less operable at the same time. This is the "Unreliability Tax": as you add reasoning depth to handle edge cases, the debug surface area grows combinatorially, not linearly [1].
The Math: If a step has 97% reliability, a 10-step agentic chain has a total success rate of just ~74% ($0.97^{10}$). Reliability decays multiplicatively (back-of-the-envelope, assumes independent steps).
Why agentic RAG scales poorly in production
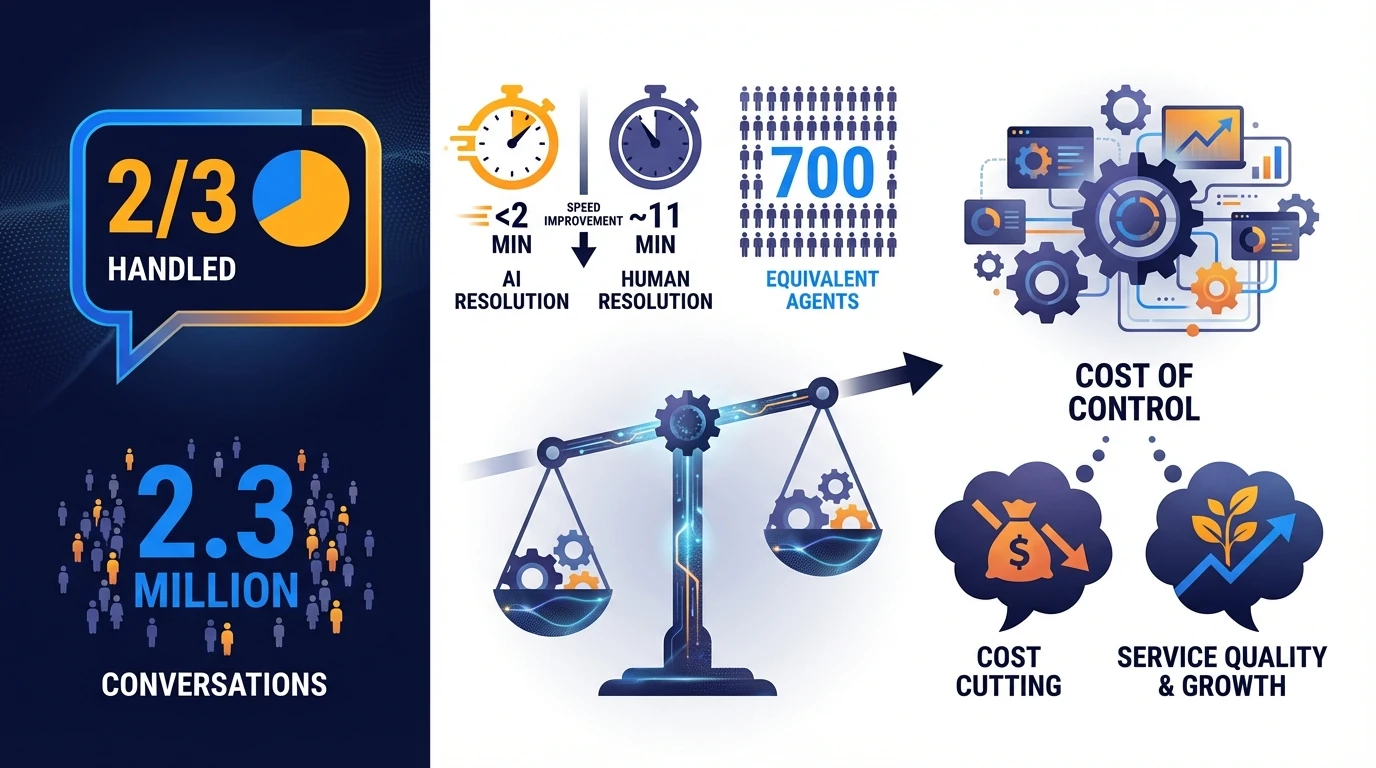
Public case study: Klarna’s customer service AI assistant (why “control” becomes the cost)
A concrete public example of “LLM costs are architectural” is Klarna’s customer service AI assistant.
Klarna reported that the assistant:
- handled roughly two-thirds of customer service chats (about 2.3 million conversations in its early rollout),
- delivered resolution times of <2 minutes vs ~11 minutes previously,
- and was described as doing work equivalent to ~700 full-time agents (with reported reductions in repeat inquiries). [5]
What matters for production economics is the second-order effect.
Reuters later reported Klarna’s CEO acknowledged the company may have over-indexed on AI for cost cutting, shifting focus from “pure savings” to service quality and growth, including resuming hiring. [6]
Takeaway: once an LLM system becomes a core operational layer, the dominant cost is not the API bill.
It’s the cost of control: escalation policies, monitoring, QA, and the engineering effort to keep failure modes bounded.
(Technical note) Klarna’s stack is often discussed as moving toward a more controllable architecture, explicit routing/structured agent workflows and better observability, precisely to make production behavior operable. [7]
Specialization changes the cost curve

The alternative is specialization. Instead of treating every request as a nail for the "General Reasoning" hammer, we treat the Large Language Model as an escalation path, not a default.
By delegating well-scoped tasks to fine-tuned small models (SLMs), think intent classification, entity extraction, policy checks, we introduce a Control Surface.
In this model, aligned with the Router-First RAG reference architecture, a lightweight Router (often a small classifier (rules/logreg) or a tiny SLM) triages requests:
- Known/Simple: Route to specialized SLM (Local, Fast, Cheap).
- Ambiguous/Complex: Escalate to Reasoning Model (Remote, Slow, Expensive).
This changes the economic structure of the system:
- Fewer model calls: 80% of traffic hits deterministic or specialized paths.
- Lower operational entropy: Improving the "Intent Classifier" fixes 80% of errors without touching the complex reasoning/generation logic.
- Debuggability: You know exactly why a request went to the SLM or the LLM.
As demonstrated in technical reports for modern SLMs [3], specifically fine-tuned small models can rival larger counterparts on narrow tasks, but with a fraction of the latency and zero "creative" drift.
Economic impact: Intentional escalation
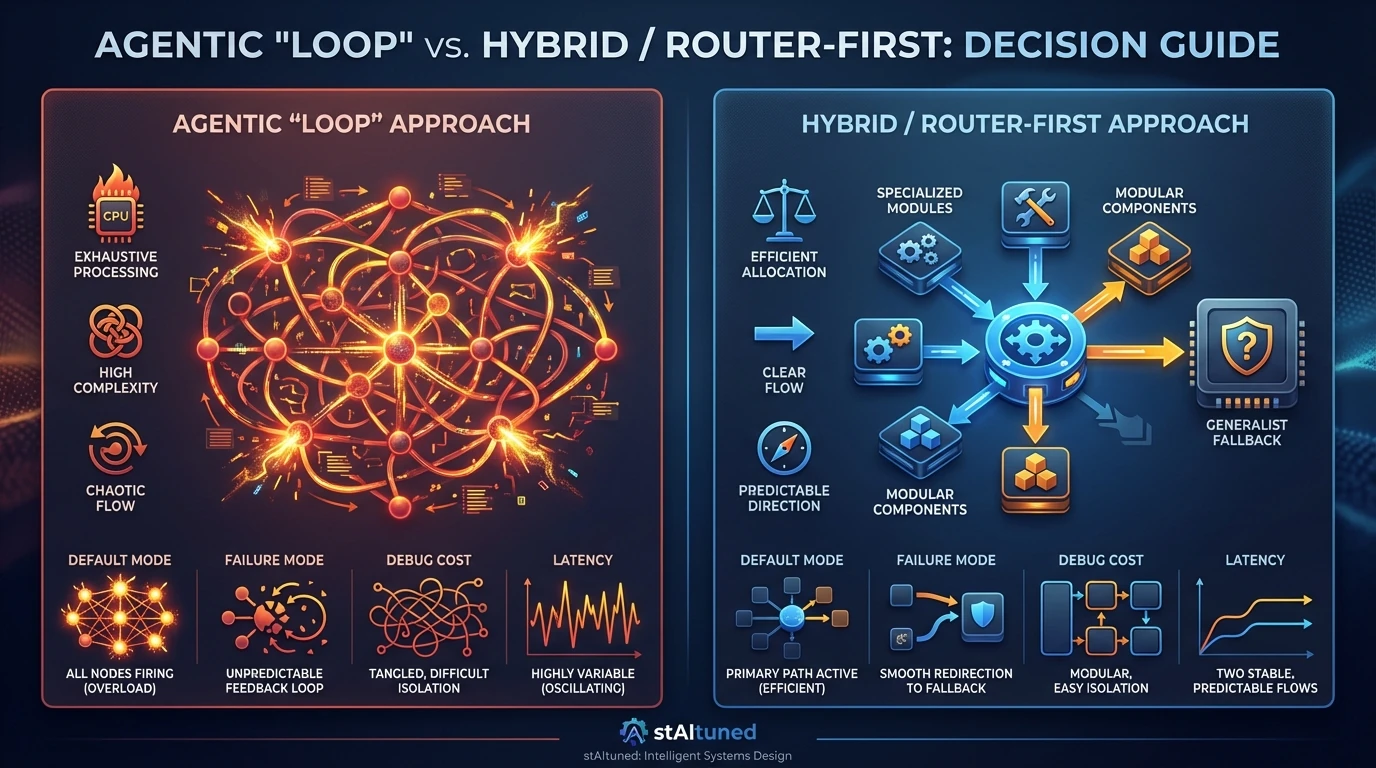
Hybrid architectures do not remove large models; they discipline them. Most importantly, routing enables intentional escalation: reasoning becomes expensive by design and is used only when its value is clear.
| Feature | Agentic "Loop" | Hybrid / Router-First |
|---|---|---|
| Default mode | Max Reasoning | Max Efficiency |
| Failure mode | Hallucination / Loop | Fallback to Generalist |
| Debug cost | High (Trace graph) | Low (Component inspect) |
| Latency | Variable (High var) | Predictable (Bimodal) |
What this does NOT claim
To be clear:
- Hybrid does not always win: For highly open-ended research or raw creativity, the general reasoning of a large LLM is irreplaceable.
- It does not remove LLMs: It disciplines them as an escalation path.
- Complexity doesn't disappear: It is redistributed from painful runtime debugging to proactive architectural design.
Operational metrics for the control surface
To move from "vibes" to engineering, track these 5 metrics for your hybrid system:
- Escalation Rate: % of traffic routed to the large model (A common target is <20%, depending on traffic mix).
- Router Confidence: Distribution of router certainty scores (Are you confident in your routing?).
- Cost per Lane: Explicit tracking of SLM vs. LLM spend.
- Disagreement Rate: How often the LLM disagrees with the SLM on sampled traffic (Ground Truth).
- P95 Latency per Lane: Is the fast lane actually fast?
When to use hybrid specialization

Use this approach when:
- Workload follows Pareto Principle: 20% of query types account for 80% of volume.
- Reliability is non-negotiable: Financial or medical advice where "creative" answers are a liability.
- Latency matters: Users expect instant feedback for simple interactions.
Avoid it when:
- Tasks are highly open-ended: "Brainstorm marketing ideas" requires the broad world knowledge of a large model.
- No training data: You cannot fine-tune an SLM without examples.
Conclusion
The main challenge in LLM systems is not capability, it is operational sustainability. Instead of asking "How much reasoning can we add?", effective AI leads ask "How much reasoning can we afford to control?".
Hybrid architectures redistribute complexity from runtime debugging to upfront architectural design. The goal is not to minimize reasoning, but to make its cost visible, bounded, and intentional.
References
- Avoiding the AI Agent Reliability Tax: A Developer’s Guide - Drew Robb, The New Stack, 2025.
- Seven Failure Points When Engineering a Retrieval Augmented Generation System - Barnett et al., 2024.
- Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone - Microsoft Research, 2024.
- Building Effective AI Agents - Anthropic Research, 2024.
- Klarna's AI assistant does the work of 700 full-time agents - OpenAI, 2024.
- Sweden's Klarna shifts AI focus from cost cuts to growth - Reuters, 2025.
- How Klarna's AI assistant redefined customer support at Klarna - LangChain Blog, 2024.
Related reading
Most requests are repetitive and well-scoped
Route by default to specialized/deterministic lanes and escalate only uncertain cases to a reasoning model.
Escalation rate stays high (>30%) for a stable workload
Refine router policy and add missing specialized lanes before increasing model size.
Debugging time dominates token spend
Prioritize observability and component boundaries over prompt tweaks.
Optimizing only per-token price
Measure total cost of ownership including retries, latency, and engineering/debug time.
Using agentic reasoning as default for all requests
Adopt router-first escalation so complex reasoning is invoked intentionally.
Weak observability in multi-step pipelines
Instrument each stage and monitor escalation rate, disagreement rate, and lane-level latency.




